3.3 基于不同特征的恶意代码检测方法
根据基于机器学习的恶意代码检测过程,因为分类器主要就是由通用型的机器学习算法完成,所以影响恶意代码检测效果的主要因素就体现在特征工程方面。即选择不同的特征进行分析,就会决定不同的检测效果。
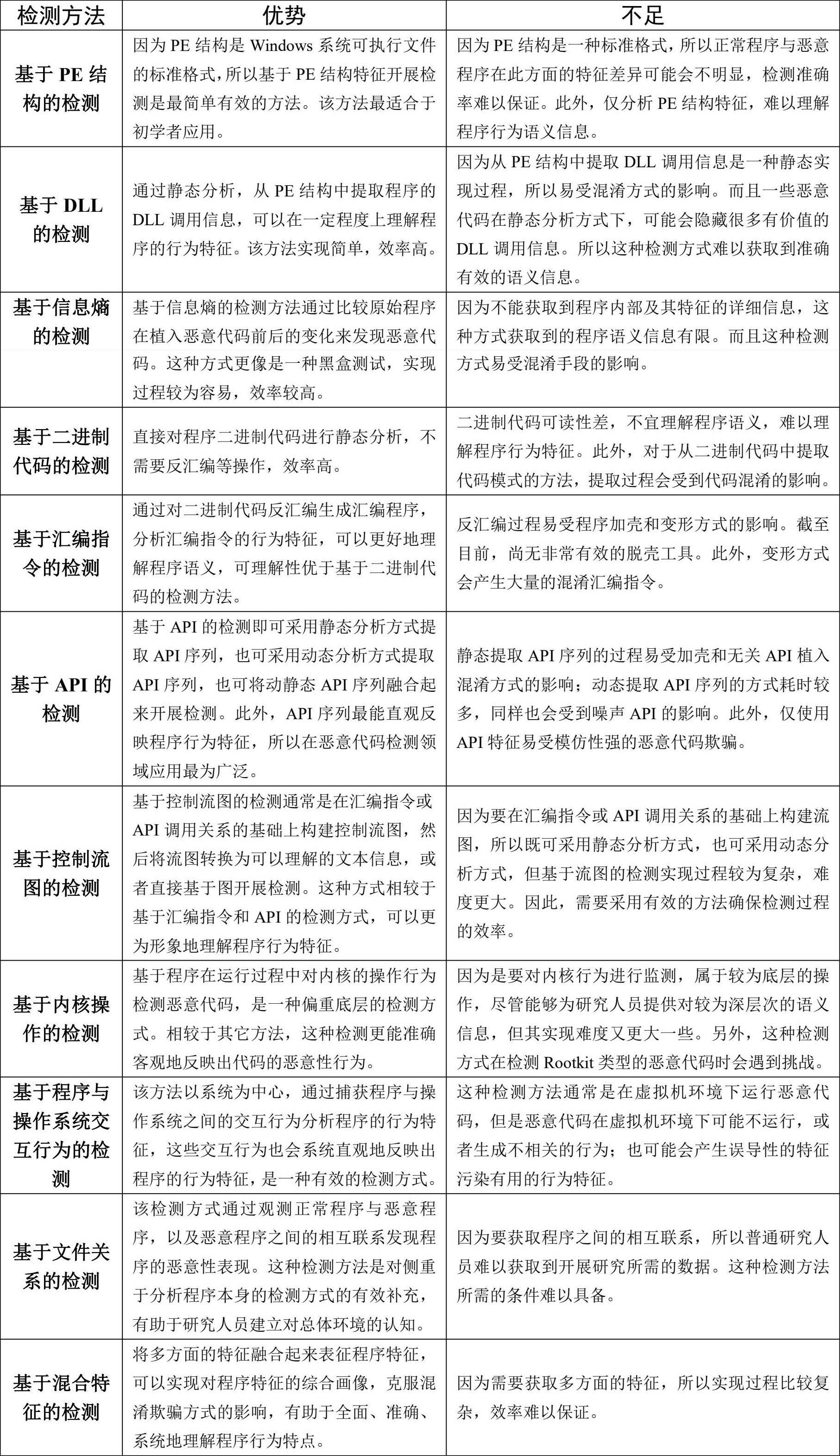
综合分析现有恶意代码检测方面的研究成果,如果按照检测过程中分析特征类型的不同进行划分,恶意代码检测方法主要包括:基于二进制代码的检测(灰度图、切片、相似性)、基于汇编程序的检测(即汇编程序中提取的Opcode、汇编指令中的堆栈)、基于PE结构的检测、基于流图的检测(CFG和DFG)、基于动态链接库的检测、基于程序与操作系统交互行为的检测、基于文件关系的检测、基于信息熵的检测、基于混合特征的检测等,如图3-2所示。对于一个开始开展本领域研究的人员来说,第一步要做的就是选择基于什么类型的特征开展恶意代码检测研究。
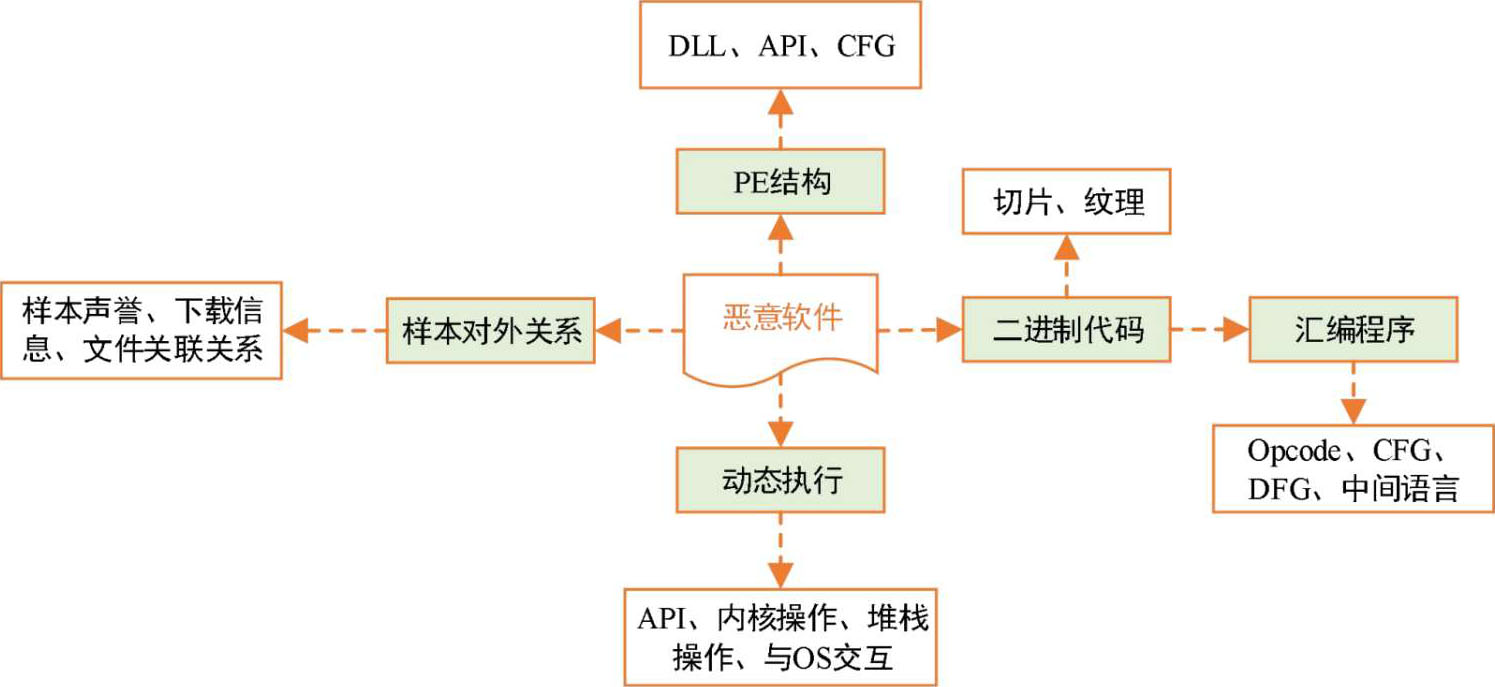
图3-2 恶意代码检测方法分类
为便于研究人员对不同类型特征的理解和应用,我们将这些不同类型的特征按照不同的层次进行划分,如图3-3所示。
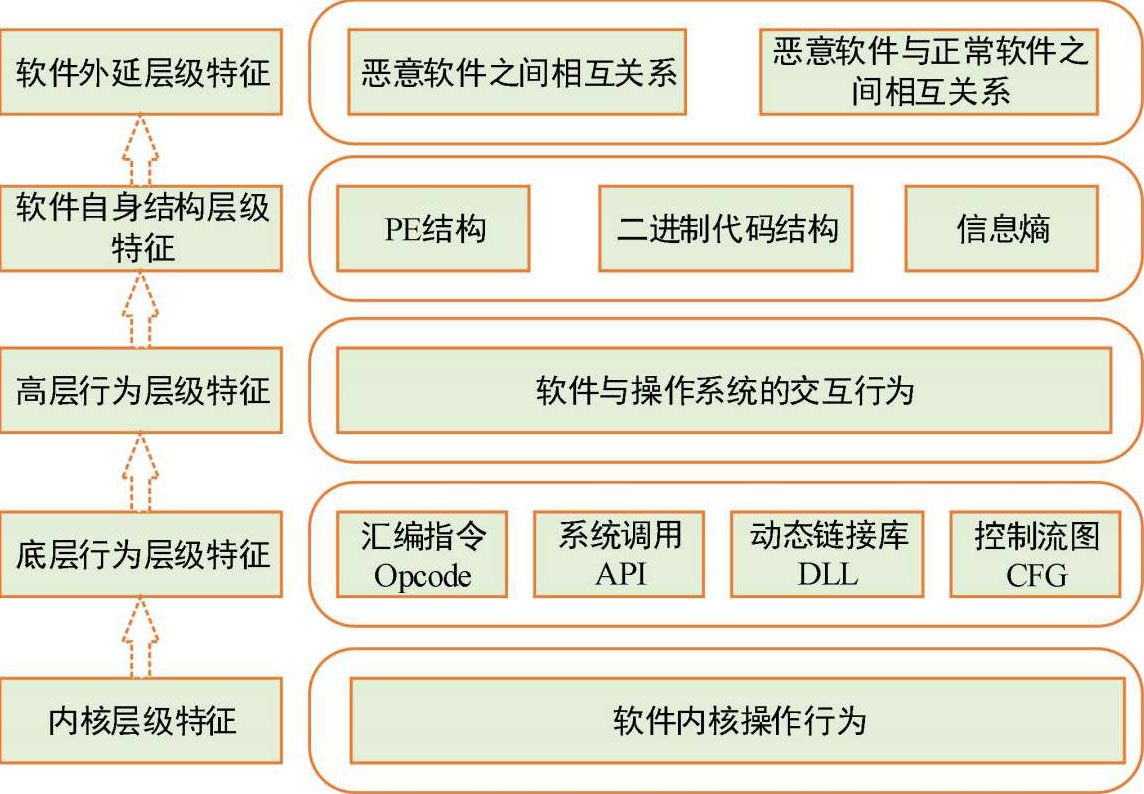
图3-3 不同类型特征的层次划分
具体解释如下:
(1)内核层级特征
主要是指代码运行过程中对内核对象的操作行为。这一层次的特征获取难度较大,但对于理解程序恶意性则更为准确。
(2)底层行为层级特征
主要是指恶意代码通过汇编指令Opcode、系统调用API、动态链接库DLL和控制流图CFG所表现出来的行为特征。这些特征是程序行为的直接体现,也被频繁应用于代码恶意性的检测。
(3)高层行为层级特征
主要是指代码与操作系统之间的交互行为,主要包括代码对系统文件的操作、对注册表的操作,以及与外界交互的网络行为。
(4)代码自身结构层级特征
这一层级主要关注代码自身的结构信息,包括PE结构、二进制代码结构、信息熵,这些特征是对代码特征的一种粗粒度表示。
(5)代码外延层级特征
主要是指恶意代码之间,以及恶意代码与正常代码之间的相互关系表现。通过挖掘代码外延表现特征,也能发现其恶意性。
以上不同类型的特征是在面对恶意代码时,分别通过直接或间接的方式获取到的。所以,按照获取特征的过程是否直接,可将以上特征按照如图3-4所示的脉络进行梳理。下面,我们也将按照这条脉络分别介绍基于不同特征的检测方法。
图3-4 获取特征的直接程度
3.3.1 基于PE结构的检测
因为PE结构是Windows平台下可执行文件的标准格式,除了从PE Header中静态提取出API调用序列之外,还可以利用PE格式的其它信息生成PE程序的特征,所以有一些研究通过分析程序的PE结构挖掘程序恶意性的蛛丝马迹。典型的基于PE结构的检测方法如表3-1所示。相较于其它特征,从PE格式中提取特征的复杂程度较低,比较适合于初入门的研究者快速理解恶意代码检测的基本过程和原理。
表3-1 基于PE结构的检测方法

基于PE结构的检测方法较为简单有效,最适合于初学者应用。但因为PE结构是一种标准格式,所以正常代码与恶意代码的特征差异可能不明显,检测准确率难以保证。此外,PE结构特征难以有效表征程序行为语义信息。
3.3.2 基于动态链接库的检测
因为PE格式的程序在实际运行过程中需要调用DLL,所以PE文件与DLL之间的调用关系,以及PE文件执行过程中所调用的DLLs之间的关联关系也是程序行为特征的直观表现。通过评估评估PE文件与DLL之间的关系,也可实现对恶意行为的检测。典型的基于DLL的检测方法如表3-2所示。
表3-2 基于DLL的检测方法

基于动态链接库的检测方法实现简单,效率高。但易受混淆方式的影响,且难以获取到准确有效的语义信息。
3.3.3 基于信息熵的检测
熵是度量信息不确定性的一个有效的性能指标。当一个正常程序被植入恶意代码段之后,其熵值前后会发生变化。此外,当一个加壳程序脱壳之后,其熵值也会发生变化。基于熵的内涵以及恶意代码检测过程中可能会涉及到的内容变化情况,一些研究人员也提出基于熵值计算实现代码检测的方法。典型的基于信息熵的检测方法如表3-3所示。
表3-3 基于信息熵的检测方法

基于信息熵的检测方法实现过程较为容易,效率较高。但其获取到的语义信息有限,且易受混淆手段的影响。
3.3.4 基于二进制代码的检测
在恶意代码检测过程中,因为通常难以获得程序的源代码,所以往往直接对程序的二进制代码进行分析。研究者可以从二进制代码中提取byte n-gram;或者将二进制转换成十进制,由此生成纹理图,开展基于图像的检测;或者对二进制代码进行切片,开展基于二进制代码切片的检测;或者从二进制代码中提取代码模式,开展基于代码模式的检测。基于二进制代码的主要检测方法如表3-4所示。
表3-4 基于二进制代码的检测方法
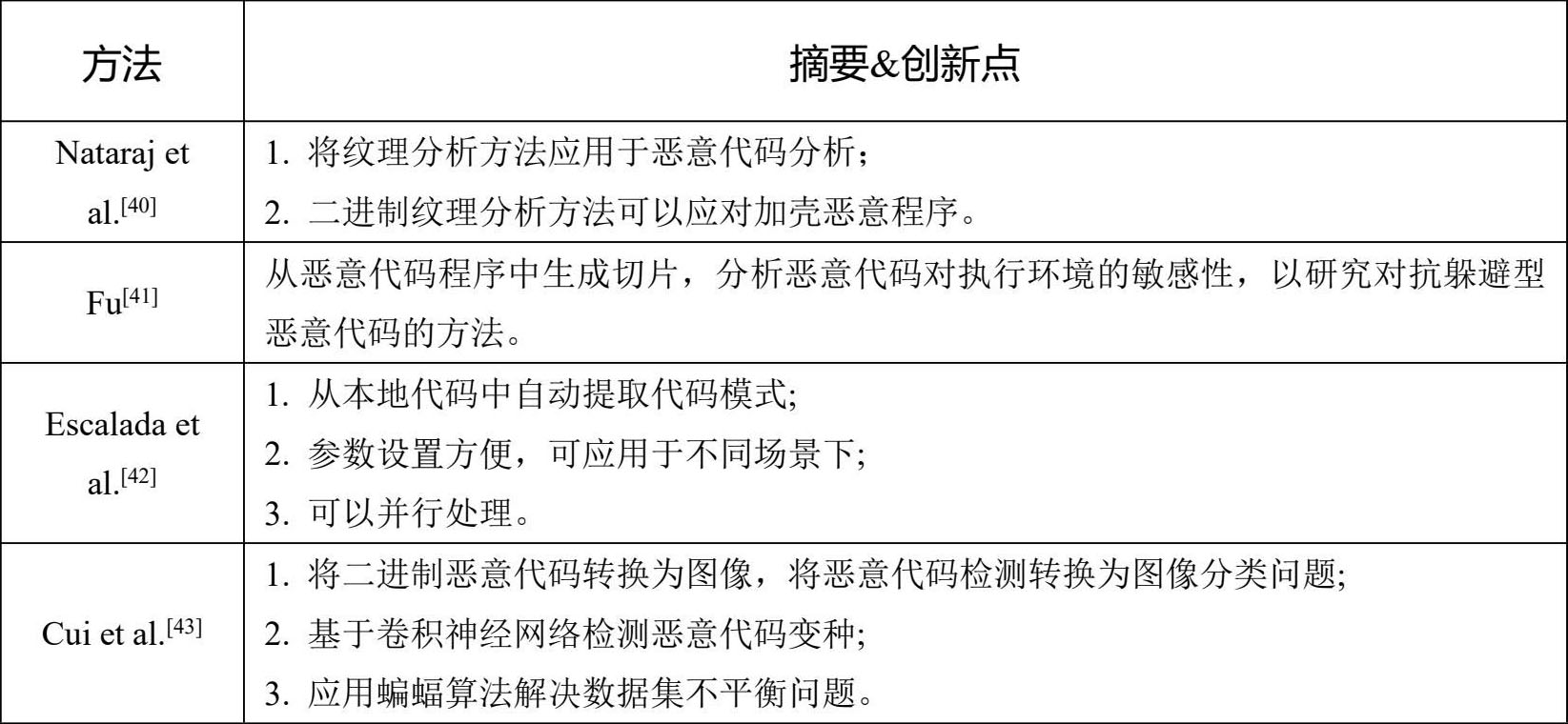
基于二进制代码的检测方法可直接对程序的二进制代码进行静态分析,不需要反汇编等操作,所以效率高。但二进制代码可读性差,难以理解程序行为特征,且易受到混淆的影响。
3.3.5 基于汇编指令的检测
恶意代码研究的一种常用方式是对二进制程序进行逆向分析,获取代码的汇编指令。相较于二进制代码,汇编指令可以更为直观地反映程序的行为特征,更有利于理解恶意代码的意图。所以,基于汇编指令的检测方法是开展恶意代码检测最为常用的方式,即使是面对最新的勒索代码,这种分析方法同样奏效。典型的基于汇编指令的检测方法如表3-5所示。
表3-5 基于汇编指令的检测
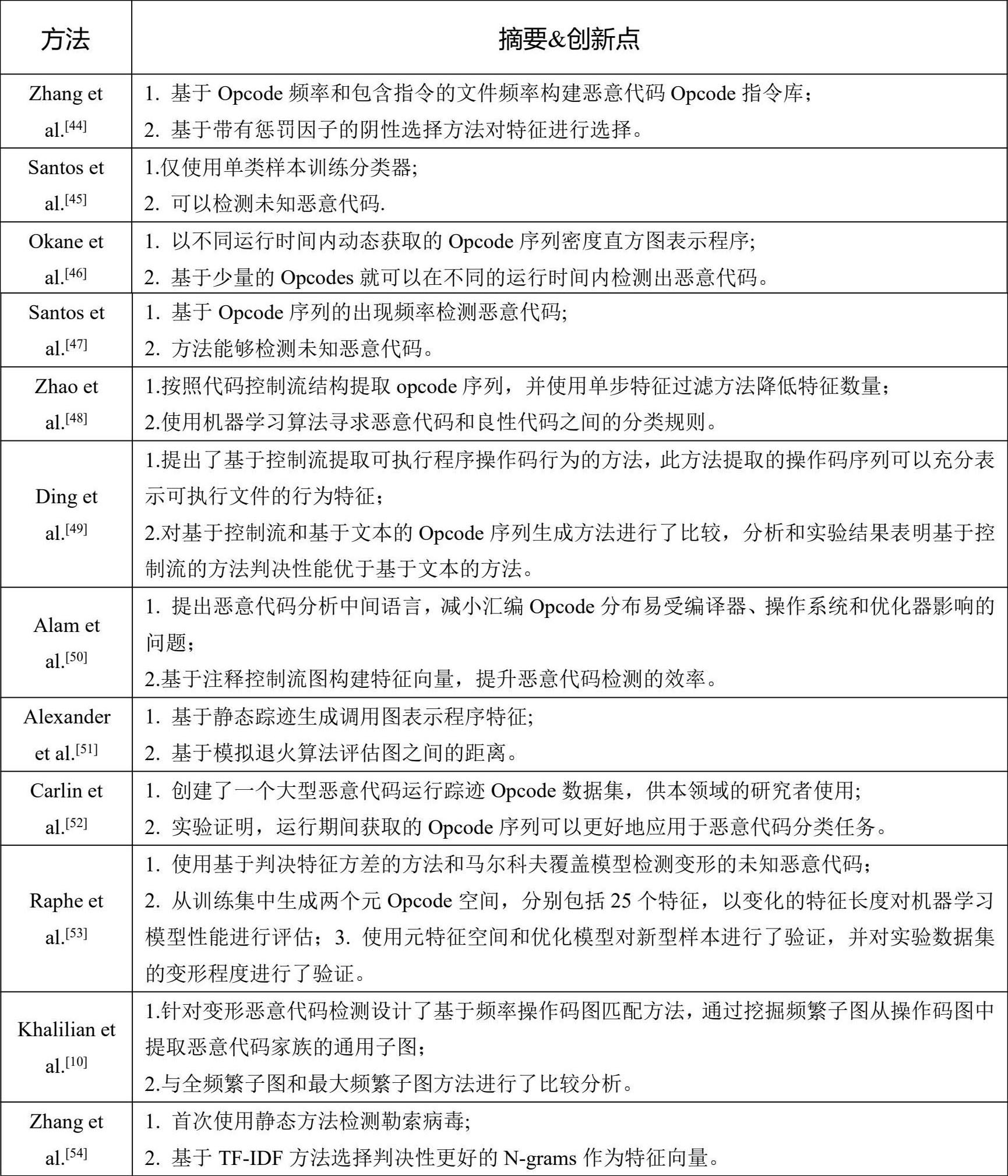
基于汇编指令的检测方法可以更好地理解程序语义,可理解性优于二进制代码,但易受程序加壳和变形方式的影响。
3.3.6 基于API的检测
通常恶意代码都是通过执行系统调用执行恶意行为,所以系统调用可被视作恶意代码的行为特征,也被最广泛地应用于开展恶意代码研究。获取系统调用API的静态方法包括:通过分析程序语义获取系统调用;使用程序状态机抽取系统调用或函数关系;通过分析PE文件头获取系统调用信息,PE文件头中包含了程序要使用的所有系统调用信息;获取系统调用的动态方法则是实际运行程序并捕获程序运行过程中的行为踪迹获取API序列。典型的基于API的检测方法如表3-6所示。基于API检测恶意代码的方法可以划分为多个层次:基本方法是直接使用API序列,比如统计API或者n-grams在样本中的出现频率作为特征值;或者是对基础API序列进行切割,构建更为抽象的语义表示,实现对程序的分割研究。
表3-6 基于API的检测方法
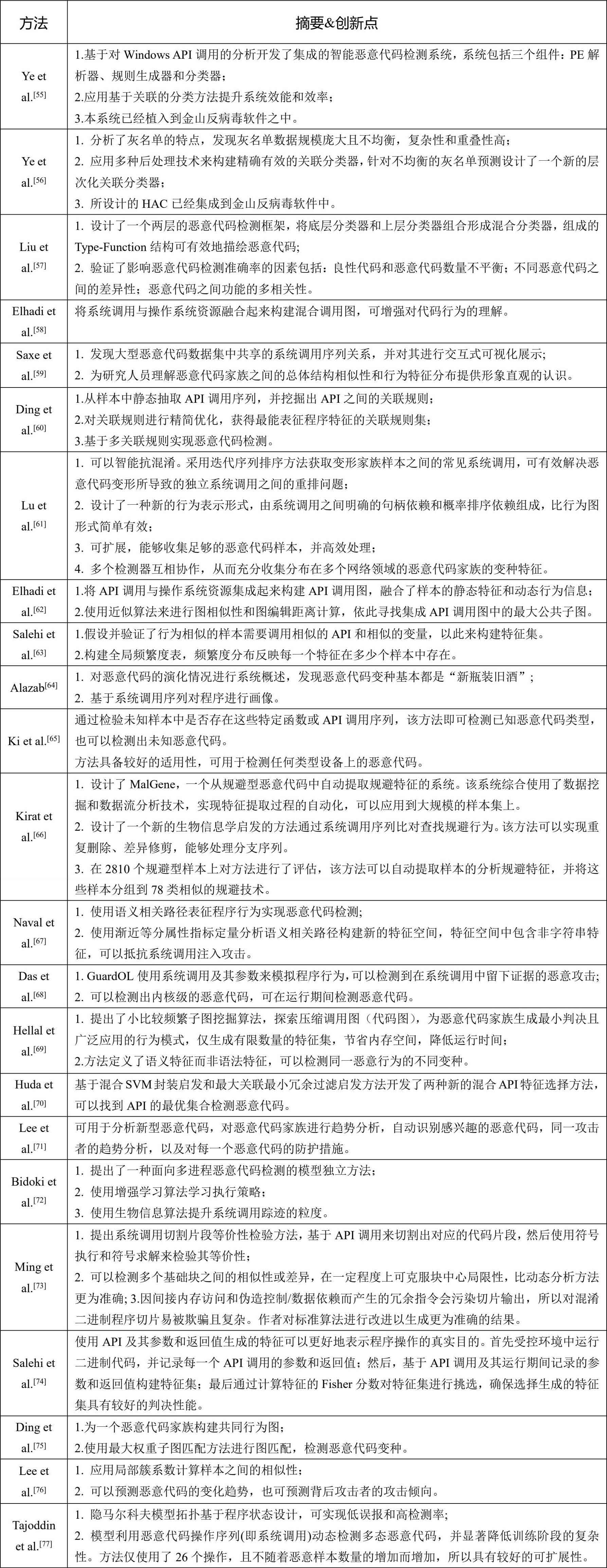
API序列最能直观反映程序行为特征,所以基于API的检测方法在恶意代码检测领域应用最为广泛。但API提取过程需要付诸一定的精力,并且仅使用API特征易受模仿性强的恶意代码欺骗。
3.3.7 基于控制流图的检测
基于Opcode和API的研究方法虽然可以反映程序行为特征,但是并未真正表示出程序的执行意图。所以,一些研究者在获取Opcode和API序列的基础上,构建控制流图,以反映出程序的真实执行意图。然后采用图匹配的方式开展检测。典型的基于控制流图的检测方法如表3-7所示。
表3-7 基于控制流图的检测方法
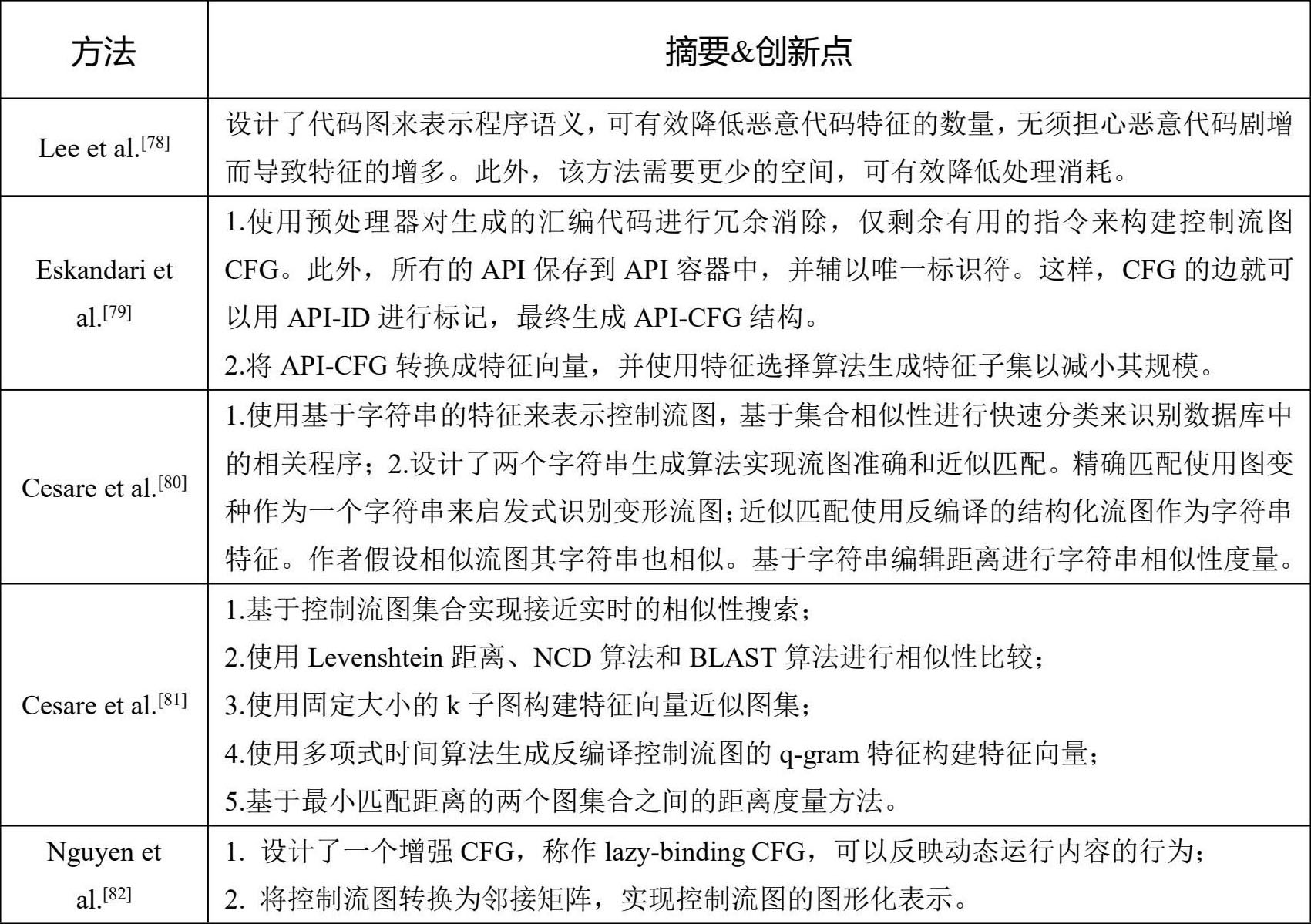
基于控制流图的检测方法可以更为形象地表示程序行为特征,但其实现过程较为复杂,难度更大。
3.3.8 基于内核操作的检测
恶意代码在实际运行过程中必然会对内核采取相关的操作,通过监测程序运行期间内核的变化情况也可以检测程序的恶意性倾向。基于内核操作行为的典型检测方法如表3-8所示。
表3-8 基于内核操作的检测方法
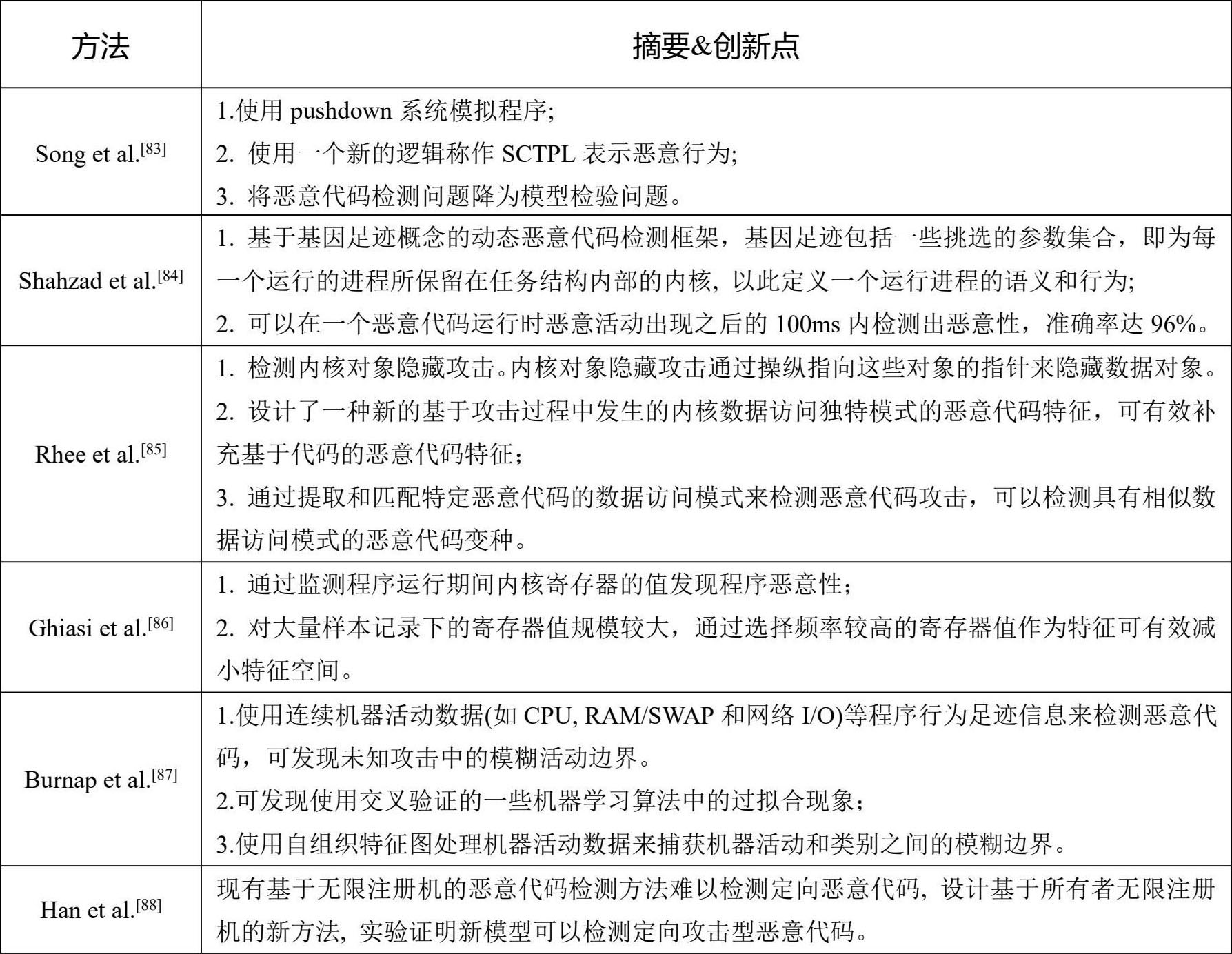
基于内核操作的检测方法是一种较为底层的检测方式,能够准确反映代码的恶意性行为。但其实现难度较大,此外这种检测方法在检测Rootkit类型的恶意代码时会遇到挑战。
3.3.9 基于程序与操作系统交互行为的检测
在分析恶意代码时,除了要关注程序自身的行为之外,程序与操作系统之间的交互行为也是值得关注的重要方面。可以通过评估程序所表现出的这些外在行为对其恶意性倾向进行评估。此领域的典型方法如表3-9所示。
表3-9 基于程序与OS交互行为的检测方法
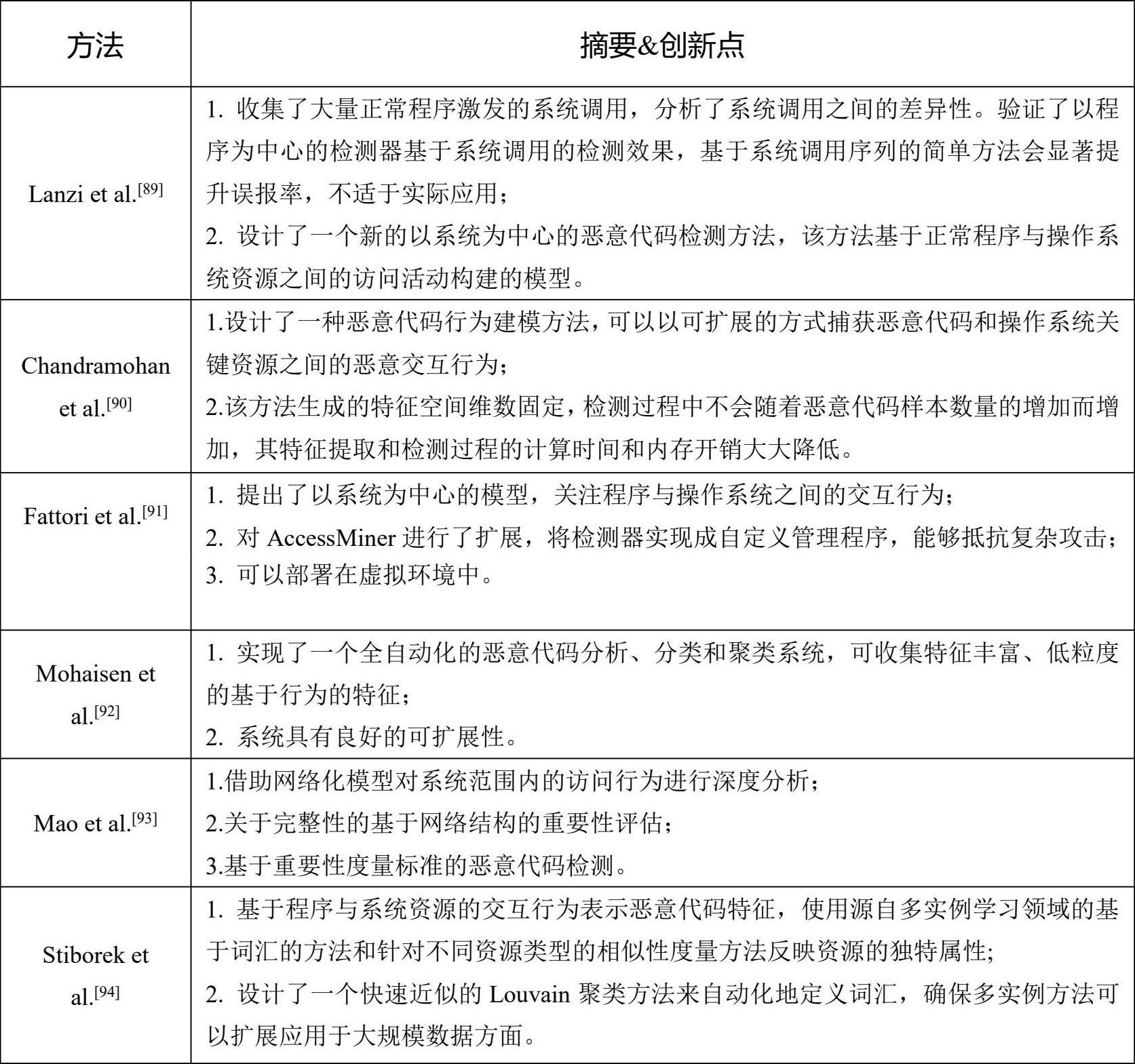
该方法以系统为中心,可直观反映程序的行为特征。但这种检测方法通常是在虚拟机环境下运行恶意代码,在遇到规避型恶意代码时会影响检测效果。
3.3.10 基于文件关系的检测
也有一些研究人员关注于恶意样本之间的相互联系,通过构建样本之间的关系网挖掘其恶意行为意图,实现对恶意样本的检测。常见的方法如表3-10所示。
表3-10 基于文件关系的检测方法

基于文件关系的检测方法是对侧重于分析程序本身的检测方法的有效补充,但受限于数据源的获取途径,通常普通研究人员难以具备条件。
3.3.11 基于混合特征的检测
随着恶意代码机理的越发复杂,单纯依赖于静态特征或动态特征的检测效果以难以满足应用要求。所以,有一些研究人员尝试集成某些静态特征和动态特征构建混合特征,实现混合分析检测。典型的研究方法如表3-11所示。
表3-11 基于混合特征的检测方法

基于混合特征的检测方法可实现对程序特征的综合描绘,检测效果最好。但特征获取过程所需工作量也较为繁重。
3.3.12 基于不同特征检测方法的比较
本节对基于不同特征的恶意代码检测方法的优劣进行比较,以方便研究者选择适合自己的研究方法。比较结果如表3-12所示。
表3-12 基于不同特征检测方法的比较