第一章
搜索引擎索引
——
在世界上最大的草垛中寻针
哈克,在咱们俩站着的地方的下面,你拿一根钓鱼竿就可以触到我钻出来的那个洞。看看你能不能找到它。
——马克·吐温,
《汤姆·索亚历险记》(
Tom Sawyer
)
搜索引擎对我们的生活产生了深远影响。绝大多数人每天都进行多次搜索查询,但我们极少会停下来思考这个令人惊叹的工具是如何奏效的。搜索引擎提供的海量信息以及搜索结果的速度与质量变得如此平常,如果我们搜索的问题没有在几秒内得到回答,我们就会感到困惑。我们倾向于忘记,每个成功的搜索引擎都是从世界上最大的草垛——万维网(www)——中寻针的。
事实上,搜索引擎提供的超级服务,不仅仅是针对搜索抛出花哨技术产生的一大堆结果。的确,每家大型搜索引擎公司都运营着一个由无数数据中心组成的国际网络,其中包括数以千计的计算机服务器和先进的网络设备。但若没有聪明的算法来组织和检索我们要寻找的信息,所有这些硬件都会变得毫无用处。因此,在这一章和下一章,我们将探究这样一些算法瑰宝——每次在进行网络搜索时,我们都会用到这些算法。我们很快就会了解到,搜索引擎的两大主要任务就是匹配(matching)和排名(ranking)。这一章将讲述一种聪明的匹配技术:元词把戏(Metaword Trick)。在下一章,我们将转而讨论排名任务,审视谷歌公司著名的网页排名算法。
匹配和排名
当你发起一次网络搜索查询时会发生什么?以这样一种高屋建瓴的视角开始会很有帮助。我已经说过,搜索有两个主要阶段:匹配和排名。在实际运行中,搜索引擎将匹配和排名组合成一个流程以实现一致性。但这两个阶段在概念上是独立的,因此我们会假设在排名开始前,匹配已经完成了。下图就给出了一个例子,图中查询的是“London bus timetable”(伦敦公共汽车时刻表),而匹配阶段则回答了“哪个网页与我的查询匹配”这个问题——在这个例子中就是所有提到“London bus timetable”的网页。
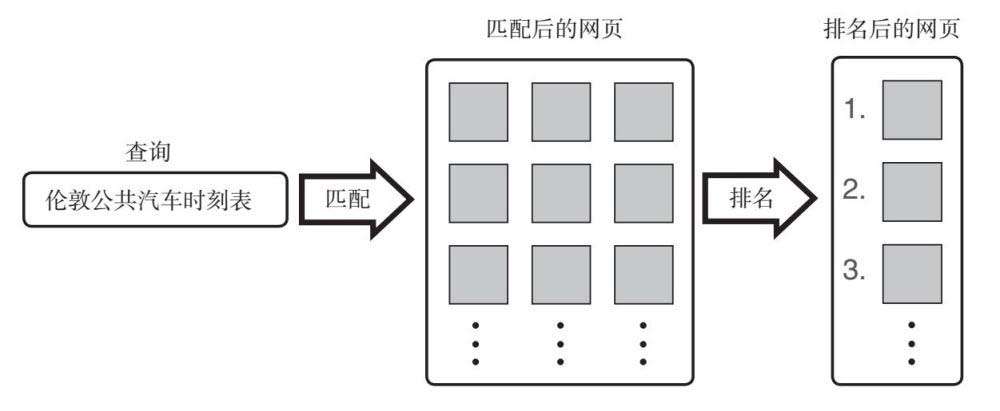
图2 网络搜索的两个阶段:匹配和排名。在第一阶段(匹配)后可能会出现数千或数百万个匹配结果,这些结果必须按照相关度在第二阶段(排名)进行排序
现实搜索引擎中的许多查询都有数百、数千,乃至数百万个“命中”,而搜索引擎用户通常只喜欢查看几个结果,5个或最多10个。因此,搜索引擎必须从大量“命中”里挑出最好的几个。一个好的搜索引擎不仅会挑出最好的几个“命中”,而且会以最有用的顺序显示它们——将最匹配的页面排在第一,然后是匹配度排名第二的页面,其后依此类推。
以正确顺序挑选出最好的几个“命中”,这被称为“排名”。排名是第二个关键阶段,紧随最开始的匹配阶段。在搜索行业的残酷世界中,搜索引擎的生死由其排名系统的质量决定。2002年,美国前三大搜索引擎的市场份额基本相当,谷歌、雅虎和MSN(微软公司旗下的门户网站)在美国的市场份额都在30%以下。MSN随后被重新包装成实时搜索引擎,之后又被命名为必应(Bing)。之后几年,谷歌的市场份额迅速扩大,同时将雅虎和MSN的市场份额分别打压到了20%以下。人们普遍认为,谷歌迅速上升为搜索行业冠军是得益于其排名算法。因此,毫不夸张地说,搜索引擎的生死由其排名系统的质量决定。不过,正如我已经提到的,我们将在下一章探讨排名算法。至于现在,让我们专注于匹配阶段吧。
AltaVista
 :互联网级别的第一种匹配算法
:互联网级别的第一种匹配算法
搜索引擎匹配算法的故事从哪里开始?一个很显然却错误的回答是从谷歌——21世纪初期最伟大的技术成功故事——开始。事实上,谷歌最初只是斯坦福大学两位学生的博士学位项目,这个故事不仅温暖人心,而且令人印象深刻。拉里·佩奇(Larry Page)和谢尔盖·布林(Sergey Brin)在1998年组装了一堆计算机硬件来运行一种新的搜索引擎。不到10年,他们的公司就成了互联网崛起时代最伟大的“数字巨人”。
不过,互联网搜索的想法已经存在很多年了。最早的商业应用是Infoseek和Lycos(两者都于1994年被推出),以及于1995年推出搜索引擎的AltaVista。20世纪90年代中期,AltaVista是搜索引擎的王者。当时我还是一名计算机科学专业的研究生,我清楚地记得自己惊叹于AltaVista搜索结果的成熟度。有史以来第一次,有一个搜索引擎能完全索引互联网上每个页面的全部文本。更可贵的是,眨眼间它就能返回结果。要继续理解这个令人回味的技术突破,我们就要从接触一个古老的(毫不夸张)概念——索引——开始。
古老的索引
索引的概念是所有搜索引擎背后最基础的思想。但索引并非由搜索引擎发明:事实上,索引的思想几乎和书写本身一样古老。比如,人类学家发现了一座具有五千年历史的古巴比伦神庙图书馆,里面按学科对楔形文字泥版进行了分类。因此,索引可以称得上是计算机科学中最古老的有用思想。
如今,“索引”这个词通常指参考书的最后一个板块。你可能想要查看的所有概念都以固定顺序(通常是按字母排序)被列出,每个概念下都列出了这个概念出现的位置(通常是页码)。因此,一本和动物有关的书也许会有一个像“cheetah(猎豹)124,156”的索引项。这个索引项意味着“cheetah”这个词在第124页和第156页出现过。

图3 一个假想的万维网,由编号为1、2和3的3个页面组成
互联网搜索引擎的索引和一本书的索引有着相同的工作原理。“书页”现在成了万维网上的网页,而搜索引擎则给互联网上的每个网页分配了一个不同的页码。(是的,互联网上虽然有很多网页——最新的数据显示有成百上千亿个——但计算机很擅长处理大量数字。)下一页的图给出了一个会让整个过程更具体的例子。想象一下万维网只由上面显示的3个短网页组成,它们分别匹配页码1、2和3。
计算机可以为这三个网页创建一个索引:首先要为出现在任一页面上的所有单词创建一份列表,然后按字母表的顺序整理这张列表。我们可以将结果称为单词表(word list)——在这个例子中是“a、cat、dog、mat、on、sat、stood、the、while”。然后计算机会一个单词一个单词地搜遍所有页面。计算机会标注每个单词所在的页码,然后再标注单词表中下一个单词的位置。最终结果显示在下图中。比如,你可以立即看到单词“cat”出现在第1页和第3页,却不在第2页;而单词“while”只出现在第3页。
通过这种简单的方法,搜索引擎就能答复许多简单的查询。比如,假设你输入查询词“cat”,搜索引擎能很快跳转到单词表中的“cat”项。(因为字母表是按字母排序的,计算机能很快找到任何一项,就像我们可以很快找到词典中的一个单词一样。)一旦计算机找到“cat”项,搜索引擎就能给出该项的页面列表——在这个例子中就是第1页和第3页。现代搜索引擎对结果的组织很合理,只摘取了返回页面的少许片段,不过,我们基本上会忽略这样的细节,而将精力集中在搜索引擎如何知道页面“符合”用户输入的查询上。

图4 一个用页码表示的简单索引
再举一个非常简单的例子,让我们来检查一下查询“dog”的步骤。在这个例子中,搜索引擎很快会找到“dog”项,并返回页码2和3。如果查询多个单词,如“cat dog”呢?这表示你正在寻找同时包含单词“cat”和“dog”的页面。通过已有的索引,搜索引擎也能很容易地查到结果。搜索引擎首先会单独查找这两个单词,找出它们分别在哪些页面中。结果是“cat”在第1页和第3页,“dog”在第2页和第3页。之后,计算机能快速扫描这两份“命中”列表,寻找同时出现在两份列表中的页码。在这个例子中,第1页和第2页被排除了,而第3页同时出现在两份列表中,因此最终答案就是第3页上的一次单独“命中”。与之极其相似的一个策略也适用于超过两个单词的查询。比如,查询“cat the sat”会得到第1页和第3页为“命中”的结果,因为它们是“cat”(1,3)、“the”(1,2,3)和“sat”(1,3)这份列表的通用元素。
就目前来看,搭建一个搜索引擎听起来相当容易。最简单的索引技术似乎运行得很好,即便查询多词也是如此。不幸的是,这种简单方法完全不能满足现代搜索引擎的需要。出现这种情况的原因有几个,不过现在我们只会关注其中之一:如何做短语查询。短语查询是指对于一个确切短语的查询,而非凑巧的一些单词出现在页面中的某些地方。比如,“cat sat”查询和cat sat查询的意义截然不同
。cat sat查询的是在任何位置包含“cat”和“sat”两个单词的页面,不考虑顺序;而“cat sat”查询的是包含单词“cat”之后紧跟单词“sat”的页面。在上面那个由三个网页组成的简单例子中,cat sat查询结果“命中”第1页和第3页,但“cat sat”查询只得到一次“命中”的结果,就在第1页。
一个搜索引擎如何才能有效地进行一次短语查询呢?继续说“cat sat”这个例子。第一步和平常的多词查询cat sat一样,从单词表中获取每个单词出现的网页列表,在这个例子中就是出现在第1页和第3页的“cat”;“sat”也一样,出现在第1页和第3页。不过搜索引擎到这里就卡住了。搜索引擎很确切地知道两个单词同时出现在第1页和第3页上,但没有办法来分辨这些单词是否以正确的顺序紧挨着彼此出现。你也许会想,搜索引擎可以返回查看原网页,看这个短语是否存在。这的确是个可能的解决方案,但效率非常低。这需要遍历每个可能包含这个短语的网页的全部内容,而且可能有海量这样的网页。记住,我们在这里打交道的是一个只由3个页面组成的极小的例子,真正的搜索引擎必须从数百亿个网页中找出正确的结果。
词位置把戏
这一问题的解决方案是让现代搜索引擎运行良好的首个真正精巧的思想:索引不仅应该存储页码,还要存储信息在页面内的位置。这些位置并不神秘:它们只是代表了一个词在页面中的位置。第3个词的位置是3,第29个词的位置是29,依此类推。例子中3个页面组成的数据集如下页图所示,我们还加上了词位置。图下面的是索引——由存储页码和词的位置得出的结果组成。我们称这种创建索引的方法为“词位置把戏”(Word-location Trick)。举几个例子,以确保大家理解了词位置把戏。索引的第一行是“a 3–5”。这意味着词“a”只在数据库里集中出现过一次,是第3页的第5个单词。索引中最长的一行是“the 1–1 1–5 2–1 2–5 3–1”。这一行可以让你知道,这组数据集中了出现单词“the”的所有具体位置。它在第1页出现过2次(位置1和5),在第2页出现过2次(位置1和5),在第3页出现过1次(位置1)。
你还记得介绍页内词位置的目的吗?是为了解决如何有效地进行短语查询这个问题。让我们来看看如何用这个新索引做一次短语查询。还是和前面一样,查询短语“cat sat”。第一步和使用旧索引时一样:从索引中提取单个词的位置,“cat”的位置是1–2、3–2,“sat”的位置是1–3、3–7。到这里还好,因为我们知道短语查询“cat sat”唯一可能的“命中”就是在第1页和第3页。但与之前一样,我们还不确定相同的短语是否出现在了这些页面中——有可能这两个单词的确出现了,但并不是以正确的顺序彼此相邻。幸运的是,从位置信息中确认这一点很容易。首先从第1页开始。根据索引信息,我们知道“cat”出现在第1页的位置2(这就是1–2的含义)。我们还知道“sat”出现在第1页的位置3(这是1–3的含义)。如果“cat”在位置2,“sat”在位置3,我们就知道“sat”紧挨着出现在“cat”之后(因为2之后立即就是3),因此我们寻找的整个短语“cat sat”必定出现在第1页,并从位置2开始。
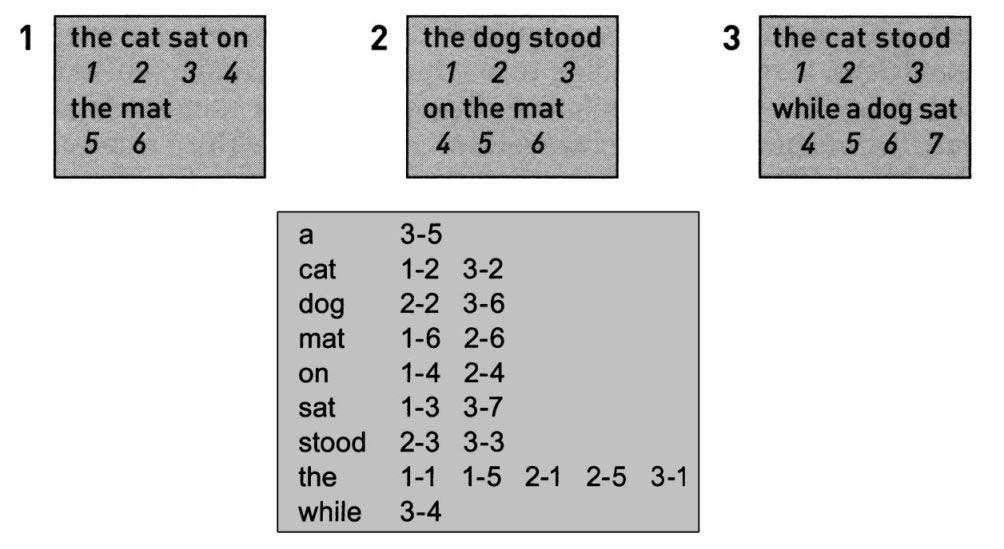
图5 上图:在3个网页里加上了页内词位置;下图:同时包含页码和页内词位置的新索引
我知道自己在这点上谈得很多,但事无巨细、从头至尾地研究这个例子,是为了让读者真正地理解为了获得答案,我们究竟使用了哪些信息。注意,我们已经为短语“cat sat”找到了一次“命中”,仅是通过查看索引信息(“cat”的位置1–2、3–2,“sat”的位置1–3、3–7)而非原始网页。这很关键,因为我们只需查看索引中的两个项,而非遍历可能包含“命中”的所有页面——而在真正进行短语查询的搜索引擎中,可能有数百万个这样的页面。总之,通过在索引中加入页内词位置,我们只需查看索引中的几行,就能找到一次短语查询“命中”,而非遍历海量页面。这个简单的词位置把戏是让搜索引擎奏效的关键之一。
事实上,我还没讲完“cat sat”这个例子。我们完成了对第1页信息的处理,但还没处理第3页的信息。对第3页的推理和第1页的处理方式很相似:“cat”出现在第3页的位置2,“sat”出现在位置7,因此它们不可能相邻——因为紧跟2之后出现的不是7。这样我们就知道,第3页并不是短语查询“cat sat”的“命中”,尽管它是多词查询cat sat的“命中”。
顺便说一下,词位置把戏不只对短语查询重要。举个例子,思考一下寻找相邻单词的问题。在一些搜索引擎中,用户可以在查询中使用“NEAR”(邻近)关键词做到这一点。事实上,AltaVista搜索引擎在早期就提供了这一功能,在本书写作时仍在提供。假设在一些特别的搜索引擎中,查询cat NEAR dog会找到“dog”前后五个位置之内出现“cat”的页面。我们如何才能在数据库中有效地执行这种查询?使用词位置会使查询变得很容易。“cat”的索引项是1–2、3–2,而“dog”的索引项是2–2、3–6。我们可以立刻看出,第3页是唯一可能的“命中”。而在第3页,“cat”出现在位置2,“dog”出现在位置6。因此这两个词之间的距离是4。因此,“cat”的确出现在“dog”前后五个位置之内,而第3页则是查询cat NEAR dog的“命中”。和前面一样,请注意这次查询的执行是多么高效:无须遍历任何网页的实际内容——相反,只参考了索引中的两个项。
不过,在实际中,NEAR查询对搜索引擎用户并不非常重要。几乎没人使用NEAR查询,绝大多数主要搜索引擎甚至不支持它们。尽管如此,能执行NEAR查询的能力实际上对现实中的搜索引擎至关重要。这是因为搜索引擎不断地在后台执行NEAR查询。要想理解其中的原因,我们先要研究现代搜索引擎面临的主要问题之一:排名。
排名和邻度
到目前为止,我们一直专注于匹配阶段:为一个给出的查询高效地找出所有“命中”的问题。不过正如之前强调的,第二个阶段“排名”对一个高质量的搜索引擎是必不可少的,它是挑选出前几个“命中”并展示给用户的阶段。
让我们更细致地来检验“排名”的概念。一个网页的“排名”究竟取决于什么?真正的问题不是“这个网页和查询匹配吗”,而是“这个网页和查询相关吗”。计算机科学家们使用“相关度”(relevance)这个术语来形容一个结果网页和某个特定查询有多么相配或这个网页多么有用。
举个具体的例子,假设你对导致疟疾的原因感兴趣,并在一个搜索引擎中输入查询malaria cause(导致疟疾)。简化考虑,假设搜索引擎对这一查询只有两个“命中”——下图显示的两个网页。现在来看看这两个网页。作为人类,你很快就知道第1页和疟疾起因有关,而第2页似乎是对刚刚发生的一些军事行动的描述,只不过恰巧使用了“cause”和“malaria”这两个词。因此,和第2页相比,第1页无疑和查询malaria cause更相关。可计算机不是人,让计算机理解这两页的主题也很难,似乎不可能让搜索引擎正确地对这两个“命中”进行排名。

图6 上两图:两个提及疟疾的样本网页;下图:从上方两个网页中创建的索引的一部分
不过,事实上,有一种很简单的方法让这个例子中的排名正确。查询词彼此相邻的网页比那些查询词相距很远的网页相关度更高。在疟疾这个例子中,“malaria”和“cause”在第1页中仅相距1个词,而在第2页中则相距17个词。(记住,搜索引擎只通过查看索引项就能高效地发现这一点,无须返回查看网页。)因此,尽管计算机并不真正地“理解”查询的主题,它也能猜测网页1比网页2更具相关性,因为网页1查询词之间的距离要比在网页2中更近。
总而言之,尽管人们不经常使用NEAR查询,搜索引擎也在不断地使用和邻度有关的信息,以提高搜索排名。而它们能高效地做到这点的原因则是,它们使用了词位置把戏。
我们已经了解到,早在距今5 000年以前,古巴比伦人就开始使用索引。而词定位把戏也不是由搜索引擎发明的:这是互联网出现以前,在另一种信息检索中用到的著名技术。不过,在下一部分,我们将了解一个看起来的确是由搜索引擎设计者发明的新把戏:元词把戏。对这一把戏和众多相关思想的精巧运用,使AltaVista搜索引擎在20世纪90年代晚期迅速成为搜索行业的“领头羊”。
元词把戏
到目前为止,我们一直都在使用极其简单的网页示例。然而,绝大多数网页拥有众多结构,包括标题、标头、链接和图片,可我们还一直认为网页只是普通的词表。接下来,我们将探索搜索引擎如何处理网页中的结构。不过,为了尽可能地保持简单,我们只会引入一层结构:网页的顶部会有一个标题,之后是页面的正文。下图显示了我们熟悉的三页示例,并附加了一些标题。

图7 一个网页范例集,每个网页都有一个标题和一段正文
实际上,要像搜索引擎一样分析网页结构,我们就需要了解更多编写网页的知识。网页是由一种特殊语言编写的,以便网络浏览器能用很好的格式展示它们。编写网页最常用的语言被称为HTML,不过HTML的细节对本次讨论来说不重要。标头、标题、链接、图片等格式化结构是用被称为元词的特殊单词编写的。比如,网页标题开始使用的元词也许是<titleStart>,而结束这个标题的元词可能是<titleEnd>。类似的,网页正文可能是以<bodyStart>开始,以<bodyEnd>结束。不要纠结于“<”“>”这些符号。它们出现在绝大多数计算机键盘上,人们通常只知道这些符号的数学意义是“小于”和“大于”。不过在这里,这些符号和数学没有任何关系,只是方便将这些元词和网页中的正常单词区分开来。
请看图8。这张图展示的内容和图7一样,但这次显示的是实际编写网页的样子,而非在网络浏览器中显示的样子。绝大多数网络浏览器都能让用户检验网页的原始内容,这需要选择名为“查看网页源代码”的菜单选项——我建议你下次有机会试验一下。在这里使用的元词,如<titleStart>和<titleEnd>,是帮助你理解虚构的、易于辨认的示例。在真实的HTML中,元词被称作标签(tag)。HTML中开启和结束标题的标签是<title>和</title>,你可以在使用“查看网页源代码”的菜单选项后搜索这些标签。
在创建一份索引时,囊括所有元词是件很简单的事,你只要像存储正常单词一样存储元词位置就行。下页的图显示了从带有元词的3个网页中创建的索引。看一下这张图,确保自己理解了其中所有的奥秘。比如,“mat”的项是1–11、2–11,这表示“mat”是第1页的第11个词,也是第2页的第11个词。元词位置的解读也一样,“<titleEnd>”的项是1–4、2–4和3–4,也就是说“<titleEnd>”是第1页、第2页和第3页的第4个词。

图8 和图7一样的网页集,但展示的是用元词编写的情况,而非在网络浏览器中显示的样子
我们称这种和索引普通单词一样索引元词的简单把戏为“元词把戏”。这个把戏也许看起来简单得可笑,但元词把戏在让搜索引擎执行精确搜索和高质量排名上扮演了至关重要的角色。举个简单例子证明。假设在某个时候,有个搜索引擎支持使用IN关键词的特殊查询,因此像boat IN TITLE这样的查询只会得到在网页标题中包含单词“boat”(船)的网页的结果,而查询giraffe(长颈鹿)IN BODY则会找到在正文中包含“giraffe”的网页。请注意,绝大多数搜索引擎并不完全按照这种方法提供IN查询,但一些搜索引擎可以通过让你点击“高级搜索”选项,详细说明查询词必须出现在标题或一份文件的特定位置来实现同样的效果。我们假定IN关键词存在,以便更容易解释。事实上,在写作本书时,谷歌已经可以让用户通过使用关键词intitle进行标题搜索了:因此,在谷歌中查询intitle:boat,将找到标题中带有“boat”的网页。自己试试吧!
让我们来看看,在下面图9和图10由三个网页组成的示例里,搜索引擎如何有效地执行查询dog IN TITLE。首先,搜索引擎提取“dog”的索引项,也就是2–3、2–7和3–11。然后(这可能有点儿出人意料,但请忍耐片刻)搜索引擎会同时提取<titleStart>和<titleEnd>的索引项。
<titleStart>的索引项是1–1、2–1和3–1,<titleEnd>的索引项是1–4、2–4和3–4。这些提取信息全部显示在下图中,你可以忽略那些圈和框。

图9 图8中的网页(包括元词)的索引
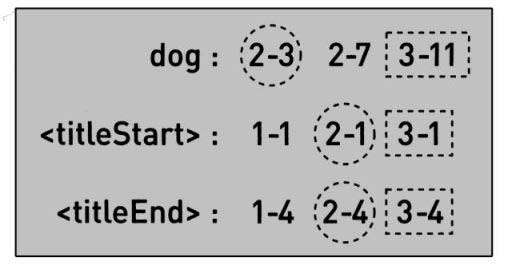
图10 搜索引擎如何执行搜索dog IN TITLE
之后,搜索引擎开始扫描“dog”的索引项,检查其“命中”,看是否有哪个“命中”出现在标题内。“dog”的第一个“命中”是圈起来的项2–3,代表其是第2页的第3个词。通过一并扫描<titleStart>的项,搜索引擎就能知道第2页的标题从哪儿开始——索引项的第一个数字要以“2–”开始,也就是被圈的项2–1,即第2页的标题从第1个单词处开始。同样地,搜索引擎能知道第2页的标题在哪儿结束。搜索引擎只要扫描索引项中的<titleEnd>,寻找以“2–”开始的索引项数字即可,在这个例子中就是停止在被圈的项2–4处,表明第2页的标题在第4个词处结束。
我们目前已知的所有东西都被图中圈住的项总结了。它们告诉我们第2页的标题从第1个词开始,到第4个词结束,而“dog”这个词是第3个词。最后一步很简单:因为3大于1、小于4,所以我们能肯定“dog”的这次“命中”确实出现在一个标题中,因此第2页应该是查询dog IN TITLE的“命中”。
现在搜索引擎可以转而寻找“dog”的第二个“命中”,也就是2–7(第2页的第7个词),但因为我们已经知道第2页是“命中”,因此可以忽略2–7这个项,而转向下一个“命中”3–11(由一个框标记)。这表示“dog”是第3页的第11个词。于是我们开始跳过被圈住的<titleStart>和<titleEnd>项,寻找以“3–”开始的项。有一点需要重点注意,我们不必回到每行的开始,而是可以从之前扫描“命中”的地方重新开始。在这个简单的例子中,以“3–”开始的项恰好彼此相邻——<titleStart>是3–1,<titleEnd>是3–4。为便于参考,我们将这两个数字用框围了起来。接下来,我们又面临判定“dog”在3–11的“命中”是否位于标题内的问题。框内信息告诉我们,它们都是在第3页,“dog”是第11个词,而标题从第1个词开始,到第4个词结束。因为11大于4,所以“dog”的这次“命中”出现在标题之后,也就是不在标题内。网页3并不是查询dog IN TITLE的“命中”。
元词把戏能让搜索引擎以极其高效的方式回应有关一个文件结构的查询。上面的例子只是搜索页面标题内的词,但类似的技术能让用户搜索超链接、图片描述和网页其他有用部分内的词。而且所有这类查询都可以像上面的例子一样得到高效回应。正如我们之前讨论过的查询,搜索引擎无须返回查看原始网页:搜索引擎只需查阅小部分索引项,就能回应查询。同样重要的是,搜索引擎只需遍历每个索引项一次。还记得我们在完成处理第2页的首个“命中”后,转向第3页的可能“命中”时发生了什么吗?搜索引擎并没有返回索引项<titleStart>和<titleEnd>的开端,而是从之前离开的地方继续进行扫描。这也是让IN查询高效的关键因素。
标题查询和其他取决于网页结构的“结构查询”类似于之前讨论的NEAR查询,虽然人们极少执行结构查询,但搜索引擎无时无刻不在内部使用它们。我们之前提过原因:搜索引擎的生死由其排名的质量决定,而通过利用网页结构,排名质量能够得到大幅提升。比如,标题中有“dog”的网页包含与狗有关信息的可能性,要比在网页正文中提及“dog”的网页大得多。因此,当一名用户输入简单的查询dog时,搜索引擎能在内部执行一个dog IN TITLE查询(即便用户并未详细地要求这一点),以寻找最有可能与狗有关的网页,而非只是恰好提到狗的网页。
索引和匹配把戏并非全部内容
搭建一个搜索引擎并不是一件容易的事情。最终成品就像一台巨大的复杂机器,它带有许多不同的轮子、发动机和杠杆。这些装置都必须安装正确,系统才能有用。因此,单靠在本章中出现的两个把戏并不能解决创建一个高效搜索引擎索引的问题,意识到这一点很重要。不过,词位置把戏和元词把戏无疑展现了真正的搜索引擎构建和使用索引的风格。
元词把戏的确帮助过AltaVista——其他搜索引擎则失败了——成功地在整个互联网中寻找有效匹配。我们之所以知道这一点,是因为AltaVista在1999年递交的美国专利文件《索引的限制搜索》(“Constrained searching of an index”)中描述了元词把戏。不过,AltaVista超级精巧的匹配算法并不足以让其从搜索行业波涛汹涌的早期脱颖而出。正如我们已经知道的,有效匹配只是高效搜索引擎的一大挑战,另一大挑战是对匹配网页进行排名。正如我们将在下一章中看到的,一种新排名算法的出现足以让AltaVista相形见绌,并让谷歌一跃升至网络搜索世界的最前沿。

