深度学习:能力惊人但也力有不逮
第一篇阐述深度学习的学术论文发表于1967年,但这项技术却花了近50年的时间才得以蓬勃发展,之所以经历了这么长的时间,是因为深度学习需要海量的数据和强大的算力,才能训练多达几千层的神经网络。如果把算力比作AI的引擎,那么数据就是AI的燃料,直到最近10年,算力才变得足够高效,数据才变得足够丰富。如今,智能手机所拥有的算力,相当于1969年美国国家航空航天局(NASA)把尼尔·阿姆斯特朗送上月球时所用电脑算力的数百万倍。除算力的大幅提升外,数据量的增长也不遑多让——2020年的互联网数据量几乎是1995年时的1万亿倍。
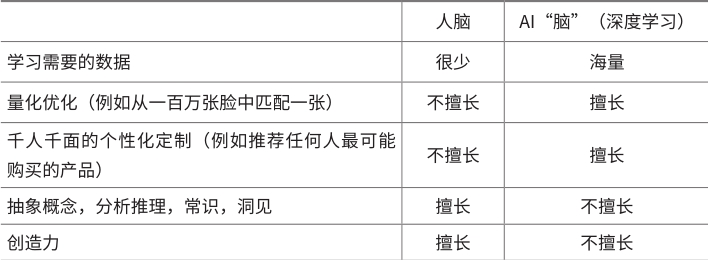
尽管深度学习的最初灵感来源于人类的大脑,但二者的运作方式截然不同:深度学习所需要的数据量远比人脑所需要的多得多。可是一旦经过大数据训练,它在相同领域的表现将远远超过人类(尤其是在数字的量化学习,例如挑选某人最可能购买的产品,或从100万张脸中挑选最匹配的一张)——相对来说,人类在同一时间内只能把注意力放在少数几件事情上面,而深度学习算法却可以同时处理海量信息,并且发现在大量数据背后的模糊特征之间的关联,这些模糊特征不仅复杂而且微妙,人类往往无法理解,甚至可能不会注意到。

图1-2 深度学习的最初灵感来源于人类的大脑
(图片来源: dreamstime/TPG)
此外,在借助大量数据进行训练时,深度学习可以针对每一个用户提供定制化的服务——基于海量数据中较相似用户的数据,对每个用户做出贴切的预测,以达到千人千面的效果。例如,当你访问淘宝时,它的AI算法会在首页醒目的位置向你重点推荐你可能愿意下单购买的商品,刺激你的消费欲,让你最大限度地在淘宝消费。AI算法推荐这些商品所依据的,不仅仅是你过去的浏览痕迹,也包括和你画像相似的其他用户的浏览痕迹。当你刷抖音上的短视频时,系统的AI算法会让你总能刷到感兴趣的内容,尽量延长你在该应用程序上的停留时间。淘宝和抖音的AI算法是定制化的,会针对不同的用户分别考量与之相类似的用户的特征,最终为其展示不同的个性化内容——同一个内容,可能在你眼里根本一文不值,但我会觉得很有价值——这种有针对性的精准定制化服务所带来的用户点击率和购买率,比传统的静态网站通常所使用的内容推送方法要好很多。
深度学习的能力非常强大,然而它并不是“包治百病”的灵丹妙药。
虽然深度学习拥有人类所缺乏的并行处理海量数据的“绝技”,但不具备人类在面对决策时独一无二的汲取过去的经验、使用抽象概念和常识的能力。
与人类相比,深度学习想要充分发挥作用,离不开海量的相关数据、单一领域的应用场景以及明确的目标函数,这三项缺一不可,如果缺少其中任何一项,深度学习将无用武之地。如果数据太少,AI算法就没有足够多的样本去洞察数据背后的模糊特征之间的有意义的关联;如果问题涉及多个领域,AI算法就无法周全考虑不同领域之间的关联,也无法获得足够的数据来覆盖跨领域多因素排列组合的所有可能性;如果目标函数太过宽泛,AI算法就缺乏明确的方向,以至于很难进一步优化模型的性能。
我们必须了解:AI“脑”(深度学习)和人的大脑是非常不一样的,从学习方法到擅长领域:
表1 人脑和AI“脑”的差别和擅长