1.5 抽象的层次性
除抽象概念之外,另一个我们必须要深入理解的概念就是抽象的层次性。小到一个方法要怎么写,大到一个系统要如何架构,以及第3章中介绍的结构化思维,都离不开抽象层次。
1.5.1 对抽象层次的权衡
回到毕加索的抽象画,如图1-8所示。如果映射到面向对象编程,抽象牛就是抽象类(Abstract Class),代表了所有牛的抽象。抽象牛可以被泛化成更多的牛,比如水牛、奶牛、牦牛等。每一种牛都代表了一类(Class)牛,对于每一类牛,我们可以通过实例化,得到一个具体的牛实例(Instance)。
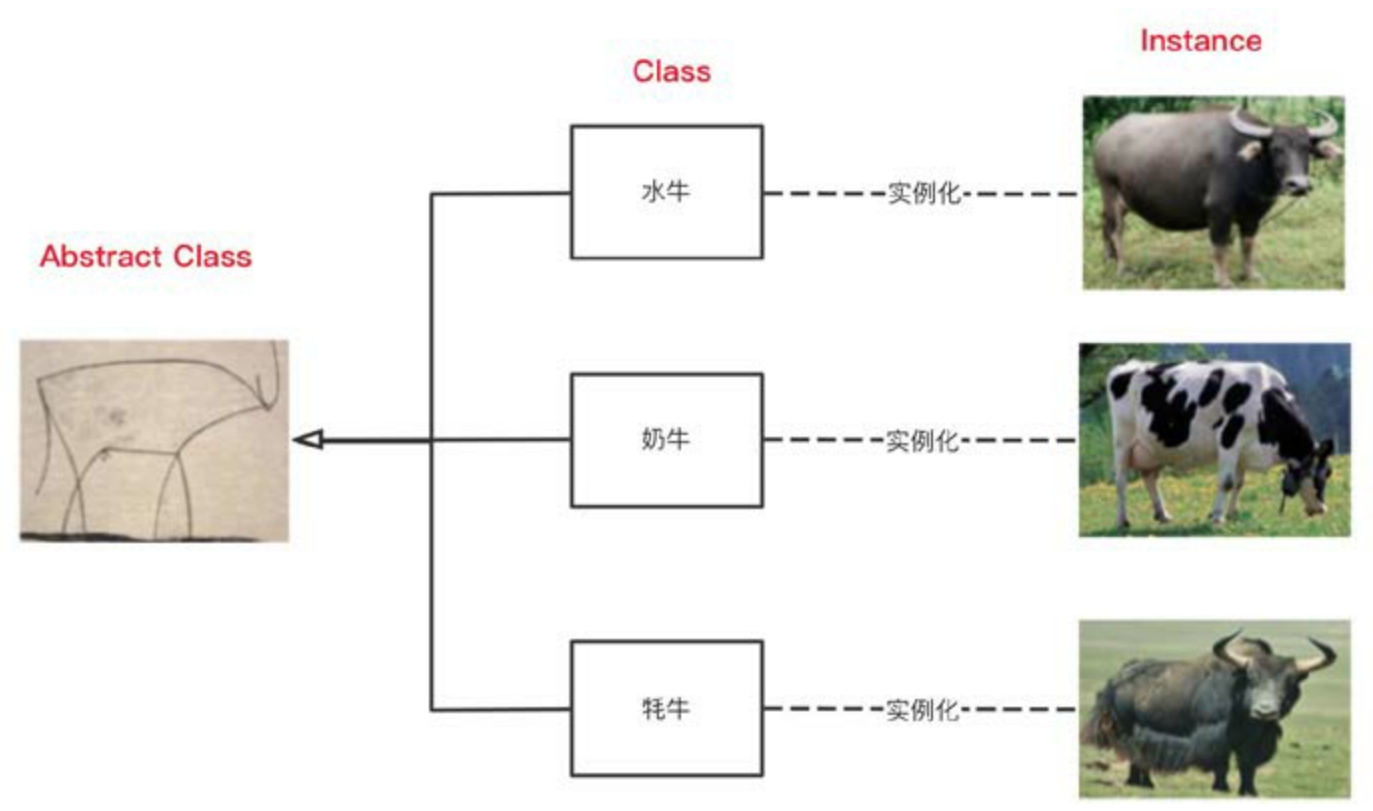
图1-8 牛的抽象层次
从这个简单的案例中,我们可以总结出抽象的3个特点。
(1)抽象是忽略细节的。抽象类是最抽象的,忽略的细节也最多,就像抽象牛,只是几根线条而已。在代码中,这种抽象既可以是抽象类,也可以是接口(Interface)。
(2)抽象代表了共同性质。类代表了一组实例的共同性质,抽象类代表了一组类的共同性质。对于上面的案例来说,共同性质就是抽象牛的那几根线条。
(3)抽象具有层次性。抽象层次越高,其内涵越小、外延越大,也就是说它的含义越小、泛化能力越强。比如,牛就要比水牛的抽象层次更高,因为它可以表达所有的牛,水牛只是牛的一个种类。
而抽象的层次性主要涉及一个概念的外延和内涵,所以在进一步讲解抽象层次之前,我们有必要先理解一下外延和内涵的概念。
抽象是以概念(词语)来反映现实的过程,每一个概念都有一定的外延和内涵。概念的外延就是适合这个概念的一切对象的范围,而概念的内涵就是这个概念所反映的对象的本质属性的总和。例如“平行四边形”这个概念,它的外延包含着一切正方形、菱形、矩形及一般的平行四边形,而它的内涵包含着一切平行四边形所共有的“有四条边,两组对边互相平行”这两个本质属性。
一个概念的内涵愈广,则其外延愈狭;反之,内涵愈狭,则其外延愈广。例如,“平行四边形”的内涵是“有四条边,两组对边互相平行”,而“菱形”的内涵除这两条本质属性外,还包含着“四边相等”这一本质属性。“菱形”的内涵比“平行四边形”的内涵广,而“菱形”的外延要比“平行四边形”的外延狭。
内涵决定外延,但外延并不决定其内涵,比如“等边三角形”和“等角三角形”有相同的外延,但是却指向不同的内涵。外延和内涵也并非总是反向变化,事实并非如此,当内涵对其外延没有影响的时候,内涵的增加并不会导致外延的变小,比如“活着的人”“活着的不超过1000岁的人”。内涵虽然增加了,但其外延是一样的。 [3]
抽象的层次性主要体现在概念的内涵和外延上,而这种层次性基本可以体现在任何事物上。比如一份报纸就存在多个层次上的抽象,“出版物”最抽象,其内涵最小,但外延最大,因为“出版物”不仅可以包含报纸,还可以包含书籍、期刊、杂志等。报纸的抽象层次如下。
● 第一层:一个出版物。
● 第二层:一份报纸。
● 第三层:《旧金山纪事报》。
● 第四层:5月18日的《旧金山纪事报》。
不同的抽象层次有不同的用途。当我要统计美国有多少种出版物时,就要用到最上面第一层“出版物”的抽象;如果我要查询旧金山5月18日当天的新闻,就要用到最下面第四层“5月18日的《旧金山纪事报》”的抽象。
对于程序员来说,对抽象层次的权衡是对我们设计能力的考验,要根据业务的需要,选择合理的抽象层次,既不能太高,也不能太低。
例如,现在要写一个关于水果的程序,我们需要对水果进行抽象,因为水果里面有红色的苹果,我们当然可以建一个RedApple的类,但是这个抽象层次有点低,只能用来表达“红色的苹果”。假如来一个绿色的苹果,你还得新建一个GreenApple类。
如图1-9所示,为了提升抽象层次,我们可以把RedApple类改成Apple类,让颜色变成Apple的属性,这样红色和绿色的苹果就都能用Apple表达了。再继续往上抽象,我们还可以得到水果类、植物类等。

图1-9 苹果的抽象层次
前面提到,抽象层次越高,内涵越小,外延越大,泛化能力越强。然而,其代价就是业务语义表达能力越弱。
具体要抽象到哪个层次,要视具体的情况而定,比如这段程序如果专门用于研究苹果,那么可能到Apple就够了;如果是卖水果的,则可能需要到Fruit;如果是做植物研究的,可能要到Plant,但很少需要到Object。
我经常开玩笑说:“为了通用性,把所有的类都设置为Object,把所有的参数都设置为Map的系统,是最通用的。”因为Object和Map的内涵最小,其泛化能力最强,可以适配所有的扩展。从原理上来说,这种抽象也是对的,万物皆对象嘛!但我们为什么不这么做呢?
这是因为,越抽象、越通用、可扩展性越强,其语义的表达能力就越弱;越具体、越不好延展,其语义表达能力却越强。 所以,对于抽象层次的权衡是我们系统设计的关键所在,也是区分普通程序员和优秀程序员的重要参考指标 。
1.5.2 软件中的分层抽象
越是复杂的问题越需要分层抽象,分层是分而治之,抽象是对问题域的合理划分和概念语义的表达。不同层次提供不同的抽象结果,下层对上层隐藏实现细节,通过这种层次结构,我们才有可能应对像网络通信、云计算等超级复杂的问题。
网络通信是互联网最重要的基础设施之一,但同时它又是一个很复杂的过程,你既要知道把数据包传给谁——IP协议,还要知道一旦在这个不可靠的网络上出现状况要怎么办——TCP协议。有这么多的事情需要处理,我们可不可以在一个层次中都实现呢?当然是可以的,但显然不科学。因此,国际标准化组织(ISO)制定了网络通信的七层参考模型(OSI),每一层只处理一件事情,下层为上层提供服务,直到应用层把HTTP、FTP等方便理解和使用的协议暴露给用户,如图1-10所示。
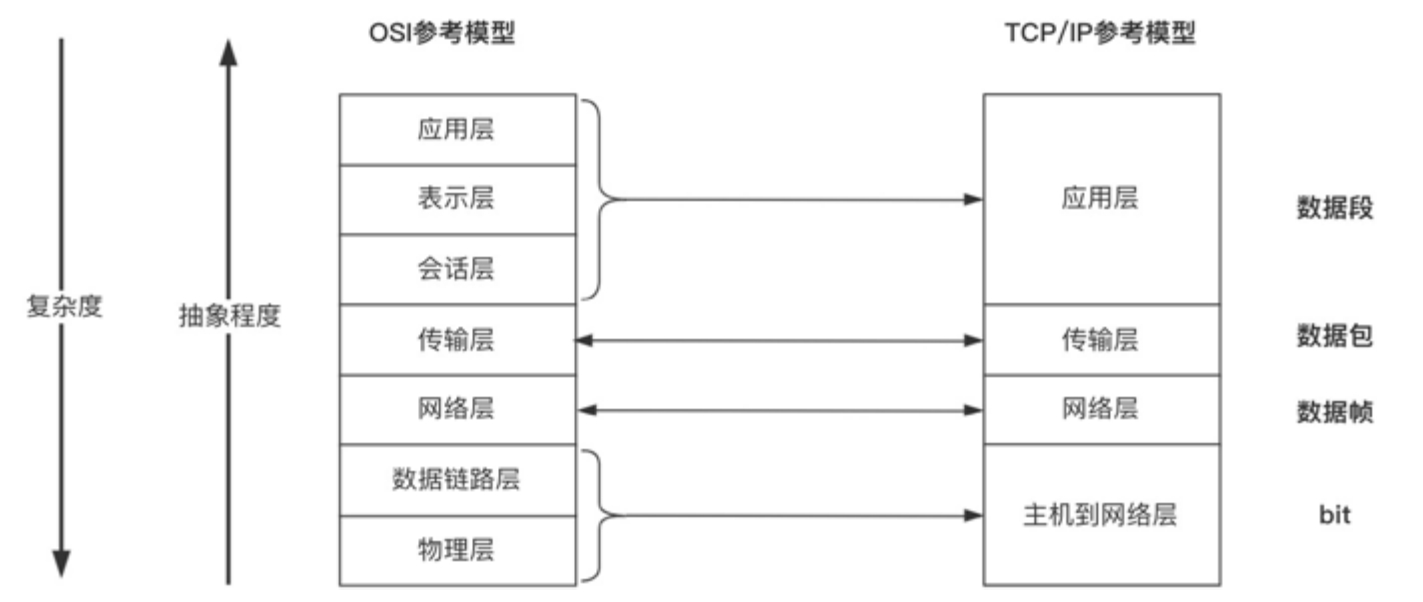
图1-10 网络协议的分层抽象
编程语言的发展史也是一部典型的分层抽象的演化史。
机器能理解的只有机器语言,即各种二进制的01指令。如果我们采用01的输入方式,其编程效率极低。学过数字电路的读者应该还记得用开关实现加减法的实验,反正我当时拨了半天,才勉强把3+4的答案算对。所以之后我们用汇编语言抽象了二进制指令,然而即使是简单的3+4,使用汇编指令实现也比较麻烦,示例如下:

于是我们进一步用C语言抽象了汇编语言,而高级编程语言Java是对类似于C这样低级语言的进一步抽象,这种逐层抽象显著提升了编程效率,如图1-11所示。
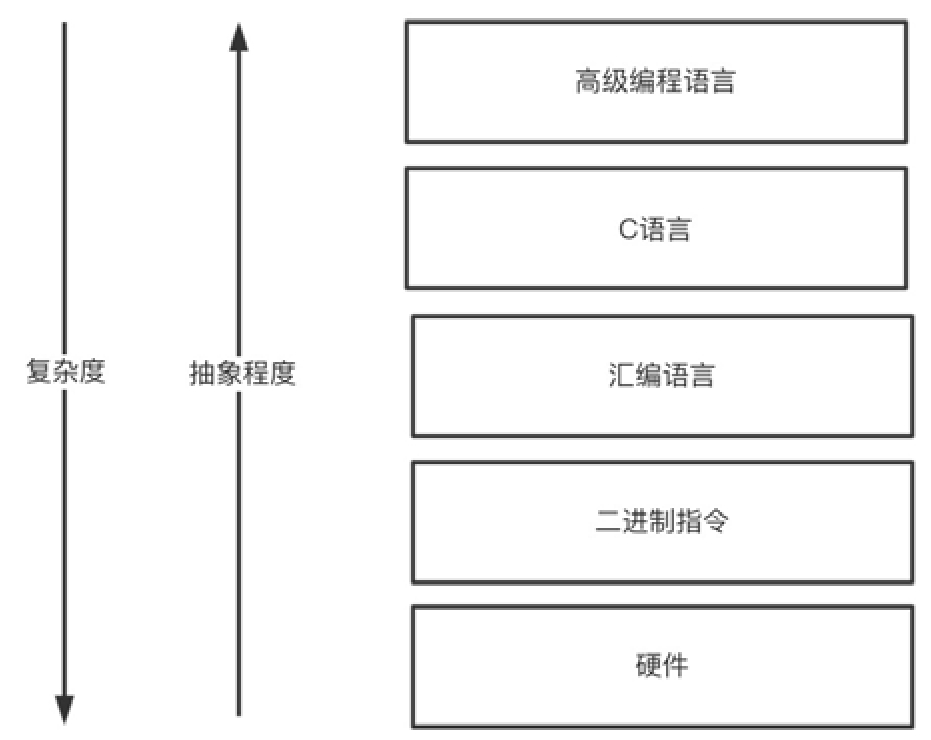
图1-11 编程语言的分层抽象
1.5.3 强制类型转换中的抽象层次问题
面向对象设计中有一个著名的SOLID原则,它是由Bob大叔(Robert C.Martin)提出来的,其中,L代表LSP,即Liskov Substitution Principle(里氏替换原则)。简单来说,里氏替换原则就是子类应该可以替换任何父类会出现的地方,并且经过替换以后,代码还能正常工作。
思考一下,我们在写代码的过程中,什么时候会用到强制类型转换呢?当然是LSP不能被满足的时候,也就是说子类的方法超出了父类的类型定义范围,为了使用子类的方法,只能使用类型强制转换将类型转成子类类型。
举个例子,在苹果(Apple)类上,有一个isSweet()方法用于判断水果甜不甜;在西瓜(Watermelon)类上,有一个isJuicy()用于判断水分是否充足的;同时,它们都共同继承一个水果(Fruit)类。
此时,我们需要挑选出甜的水果和有水分的西瓜,会编写如下一段程序:


因为pickGood()方法的入参的类型是Fruit,所以为了获得Apple和Watermelon上的特有方法,我们不得不使用instanceof做一个类型判断,然后使用强制类型将其转换为子类类型,以便获得它们的专有方法,很显然,这违背了里氏替换原则。
问题出在哪里呢?对于这样的代码,我们要如何去优化呢?仔细分析一下,可以发现,根本原因在于isSweet()和isJuicy()的抽象层次不够,站在更高的抽象层次,也就是Fruit的视角看,我们挑选的就是可口的水果,只是具体到苹果时,我们看甜度;具体到西瓜时,我们看水分而已。
因此,解决方法是对isSweet()和isJuicy()进行抽象层次提升,在Fruit上创建一个isTasty()的抽象方法,然后让苹果和西瓜类分别去实现这个抽象方法就好了,如图1-12所示。
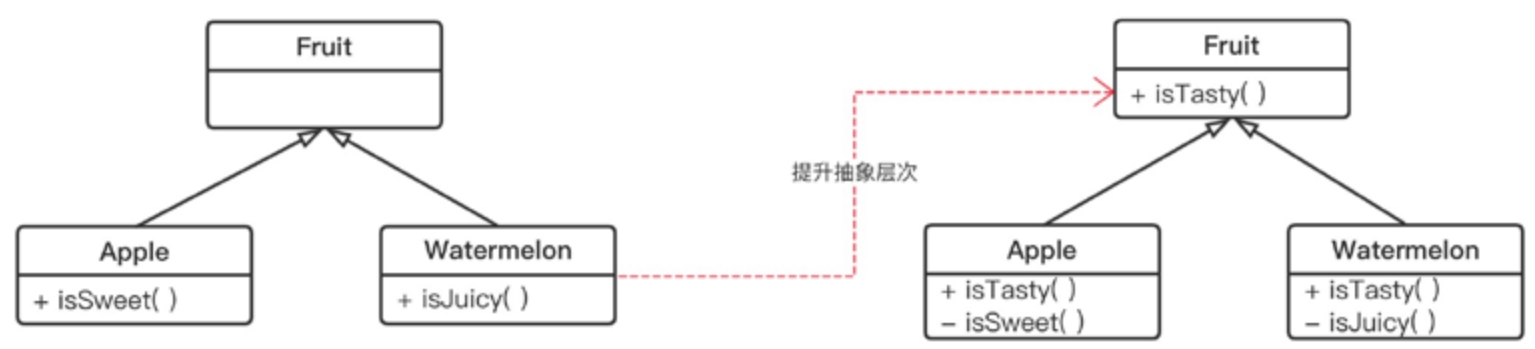
图1-12 提升抽象层次
下面是重构后的代码,通过提升抽象层次,我们消除了instanceof判断和强制类型转换,让代码重新满足了里氏替换原则,也使代码重新变得优雅了。


所以,每当在程序中准备使用instanceof做类型判断,或者用cast做强制类型转换的时候,再或者程序不满足LSP的时候,我们都应该警醒一下:好家伙!这又是一次锻炼抽象能力的绝佳机会。
1.5.4 抽象层次一致性原则
抽象层次要保持一致,一致性可以减少混乱,并降低理解成本 。比如,你把水果、苹果、香蕉归类放在一起,就会显得不协调,自己心里也会犯嘀咕:为什么要把水果和苹果、香蕉放在一起呢?水果和苹果、香蕉不是一个抽象层次的(水果比另两者高一个抽象层次)。同样,我们在写代码的时候,如果把不同抽象层次的代码放在一起,也会在无形中提高认知和理解成本。
鉴于此,抽象层次一致性原则(Single Level of Abstration Principle,SLAP)应运而生。SLAP是ThoughtWorks的总监级咨询师Neal Ford在《卓有成效的程序员》一书中提出来的概念,其思想源自Kent Beck提出的组合方法模式(Composed Method Pattern,CMP)。
SLAP强调每个方法中的所有代码都处于同一级抽象层次。如果高层次抽象和底层细节杂糅在一起,就会显得代码凌乱,难以理解,从而造成复杂性。
举个例子,假如有一个冲泡咖啡的原始需求,其制作咖啡的过程分为3步。
(1)倒入咖啡粉。
(2)加入沸水。
(3)搅拌。
其伪代码(pseudo code)如下:

这时新的需求来了,需要允许选择不同的咖啡粉,以及选择不同的风味。于是上述代码从一开始的“眉清目秀”变成了下面这样。
如果再有更多的需求过来,代码还会进一步恶化,最后就变成一个谁也看不懂的“逻辑迷宫”、一个难以维护的“焦油坑”。
我们再回来看一下,新需求的引入当然是根本原因,但是除此之外,另一个原因是新代码已经不再满足SLAP了。具体选择用什么样的咖啡粉是“倒入咖啡粉”这个步骤应该考虑的实现细节,和主流程步骤不在一个抽象层次上。同理,加糖、加奶也是实现细节。
因此,在引入新需求以后,制作咖啡的主要步骤从原来的3步变成了4步。
(1)倒咖啡粉,存在不同的选择。
(2)倒开水。
(3)调味,根据需求加糖或加奶。
(4)搅拌。
根据组合方法模式和SLAP,我们要在入口函数中只显示业务处理的主要步骤。其具体实现细节通过私有方法进行封装,并通过抽象层次一致性来保证,一个函数中的抽象应该在同一个水平上,而不是将高层抽象和实现细节混在一起。
根据SLAP,我们可以将代码重构为:

重构后的makeCoffee()又重新变得整洁如初了,实际上,这种代码重构也是一种结构化思维的体现。 在结构化思维中,有一个要点就是结构的每一层要属于同一个逻辑范畴、同一个抽象层次 。更多关于结构化思维的内容会在第3章中详细介绍。
接下来,我们看一个真实的案例。在Spring中,做上下文初始化的核心类AbstractApplicationContext的refresh()方法,可以说在如何遵循SLAP方面给我们做了一个很好的示范。


试想:如果上面的逻辑混乱、无序地平铺在refresh()方法中,其结果会是怎样的?

