02|我是一个大模型

“下一位。”
前一位传话的机器人还没出门,门口的叫号员就迫不及待地叫了起来。看样子,外面排队的人少不了,今晚估计还得加班。
门被推开了,是小二,一个刚上班没几天的年轻人。他一进门就塞给我一张纸条,嚷道:“老莫,终于排到我了!”
我是ChatGPT Model,一个大语言模型,传话的小机器人都叫我老莫。其实我也确实是一个“劳模”,每天有答不完的小纸条,隔三差五的,人类还要训练我,让我学习进步,反正是闲不下来。
把小二的纸条接过来,我掐指一算,写下回答的第一个字——“可”。再一算,写下第二个字“以”。当我再次要掐指时,小二在一旁忍不住问:“老莫,人家都说你博览群书,不管什么问题,答案都在你的脑子里,可你为啥要一字一掐,不能把答案一口气全写下来呢?”
“那你就不懂了。”我边掐指边写下第三个字“通”,说道,“博览群书没错,可我并没有现成的答案。这些答案都是我猜的。”
“猜?”小二的表情更迷糊了。
“或者用行话来说,叫预测。刚开始,我根据小纸条上问的这句话‘ 怎么给朗朗过十岁生日? ’,来计算下一个字说什么的概率比较大,结果我发现‘可’字概率高,就先把它写下来。”

◎图1.2 将“上文=怎么给朗朗过十岁生日?”作为条件,计算下一个字的概率
“一次只预测一个字?那多麻烦,为啥不计算一整段话的概率呢?”小二继续问道。
“嗯,我是在计算每一个字的条件概率。当文本里已经出现‘怎么给朗朗过十岁生日?可’了,在这个前提条件下,我又算出来下一个字是‘以’的概率最大。不断预测下一个字,整段话就出来了。看起来步骤多,但都是在重复做类似的一件事,反倒简单。”
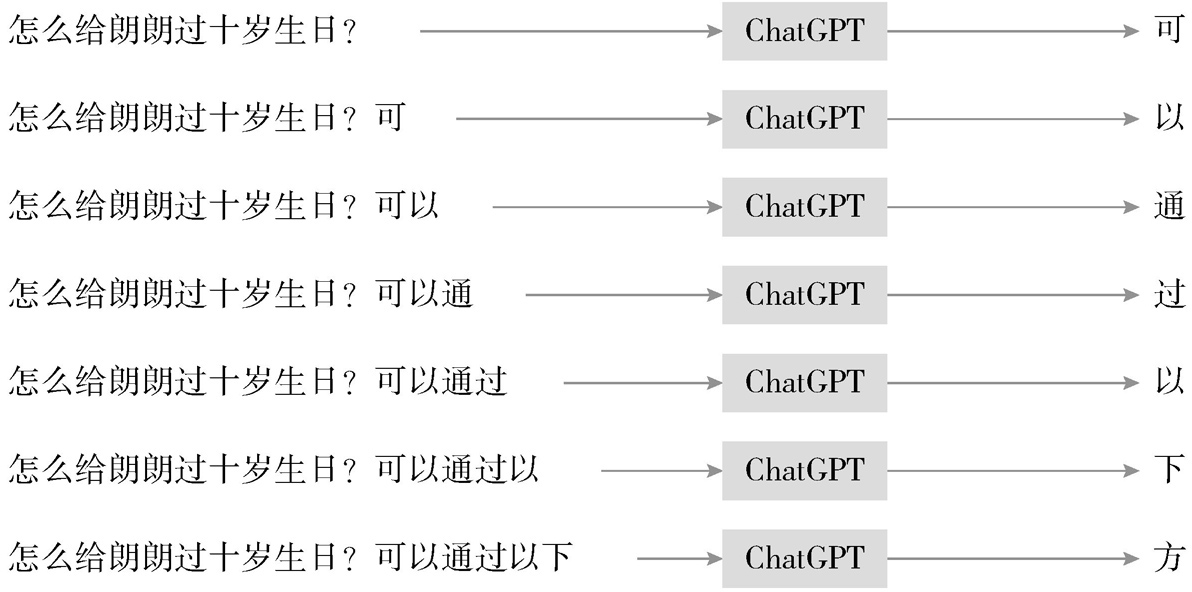
◎图1.3 ChatGPT Model连续预测下一个字的运行机制
“哦,你玩的是文字接龙啊!”
看着小二若有所思的样子,我把纸条递到他手里。
“明白了吧?我写完答案了,你赶紧回去吧,别让那边的人类等急了,当心给你差评。”
“我好像明白了……可你是怎么学会计算下一个字的概率的呢?”小二的好奇心上来了。
“那可说来话长了。”我一只手推他出门,一只手伸进门边冷水盆里,给手指头降降温,毕竟连续掐算了好几个小时,手指早已是又红又烫了。
“下一位。”
*深度扩展阅读*
语言模型被编程用于预测下一个字……其实动物,包括我们在内,也只是被编程用来生产和繁衍,而许许多多复杂和美好的东西正是来自于此。
——山姆·阿尔特曼(Sam Altman),
OpenAI首席执行官
·人工智能模型在推理阶段都做些什么?
人工智能模型的工作分为训练(training)和推理(inference)两个阶段,在跟人类聊天时,模型处于推理阶段,此时其不再调整自己的参数,而是根据已经学习到的知识来进行预测和响应,以帮助人类完成各种各样的任务。
具体来说,在跟人类聊天时,人工智能系统会执行以下步骤的工作:
1. 接收输入: 接收人类的输入,通常是一句话或一段文字。多模态大模型还可以接收图片作为输入。
2. 处理输入: 将输入的文本编码成数字向量,以便计算机理解和处理。
在把输入的内容传送到大模型做推理之前,系统会先对输入进行检测和预筛,针对不合规、不合法或不符合道德的有害问题,直接拒绝回答;针对特定的、不该随意发挥的问题,直接给出官方标准回答。
3. 进行推理: 模型会基于输入的文本使用已经训练好的神经网络模型和它在之前的对话中所学到的知识来进行推理,找到最有可能的响应。
■ChatGPT会将人类输入的文本作为上文,预测下一个标识(token)或下一个单词序列。具体来说,ChatGPT会将上文编码成一个数字向量,并将该向量输入到模型的解码器中。解码器会根据该向量生成一个初始的“开始”符号,并一步步生成下一个token或下一个单词序列,直到遇到一个“结束”符号或达到最大长度限制为止。
■ChatGPT使用了基于自回归(auto-regressive)的生成模型,也就是说,在生成每个token时,它都会考虑前面已经生成的token。这种方法可以保证生成文本的连贯性和语义一致性。同时,ChatGPT也使用了束搜索(beam search)等技术来计算多个概率较高的token候选集,生成多个候选响应,并选择其中概率最高的响应作为最终的输出。

◎图1.4 ChatGPT的概率候选词
4. 生成输出: 将推理结果转换为自然语言,以便人类理解,这通常是一句话或一段文字。
模型生成的回答文本也可能会经过系统中的合规性检测模块,确保输出内容符合要求,再输出给人类。
·中文和英文的最小预测单元有什么不同?
上文故事里我们以中文为例,模型会预测下一个字,实际上模型是预测下一个token,在中文的条件下,一个token等于一个汉字。
在处理英文时,模型通常会使用分词技术将句子中的单词分割出来,并将每个单词作为一个token进行处理。此外,模型也可以使用更细粒度的子词级别的token表示方法,以便更好地利用单词内部的信息。这种方法在处理一些英文中常见的缩写、不规则形式和新词时可能会更加有效,还能压缩词库中词的数量。
·预测下一个字的概率时,一定会选最高概率的字吗?
在生成token时,模型通常会将解码器输出的每个token的概率归一化,并根据概率选择一个token作为生成的下一个单词或标点符号。如果只选择概率最高的token,生成的响应会比较保守和重复。因此,ChatGPT通常会使用温度(temperature)参数来引入一定程度的随机性,以使生成的响应更加丰富多样。就像掷骰子一样,在概率高于临界点的token里面随机选择,概率较高的token被选中的可能性较大。
应用程序编程接口的开发者可以根据实际场景的特点和需求,对temperature值进行调整。通常情况下,较大的temperature值会有更多机会选择非最高概率token,可以产生更多样的响应,但也可能会导致生成的响应过于随机和不合理。相反,较小的temperature值可以产生更保守和合理的响应,但也可能会导致生成的响应缺乏多样性。

