一、人工智能的“大脑、五感与躯壳”
(一)脑:更快更广的思考能力
在人工智能的黎明,我们目睹了一项项科技奇迹的诞生。从简单的算法到复杂的神经网络,人类一直在追求创造一个能够模仿甚至超越人脑的“思考机器”。今天,我们站在了一个新的交汇点上,科学家们正在解锁大脑深处的原理,以此照亮前行的道路。那么,如何通过学习与模拟人脑的奥秘,构建起一台具有更快、更广、更深的思考能力的人工智能呢?
本节将引领读者走过这一发展历程,揭示人工智能模拟大脑如何从最初的理念演化到现今日益成熟的科学与技术领域,以及这场旅程如何深刻影响着我们对人脑的理解与人工智能的未来。
如下表和下图所示,人工智能大脑智慧的发展经历了以下三个阶段。
人工智能大脑智慧的发展阶段
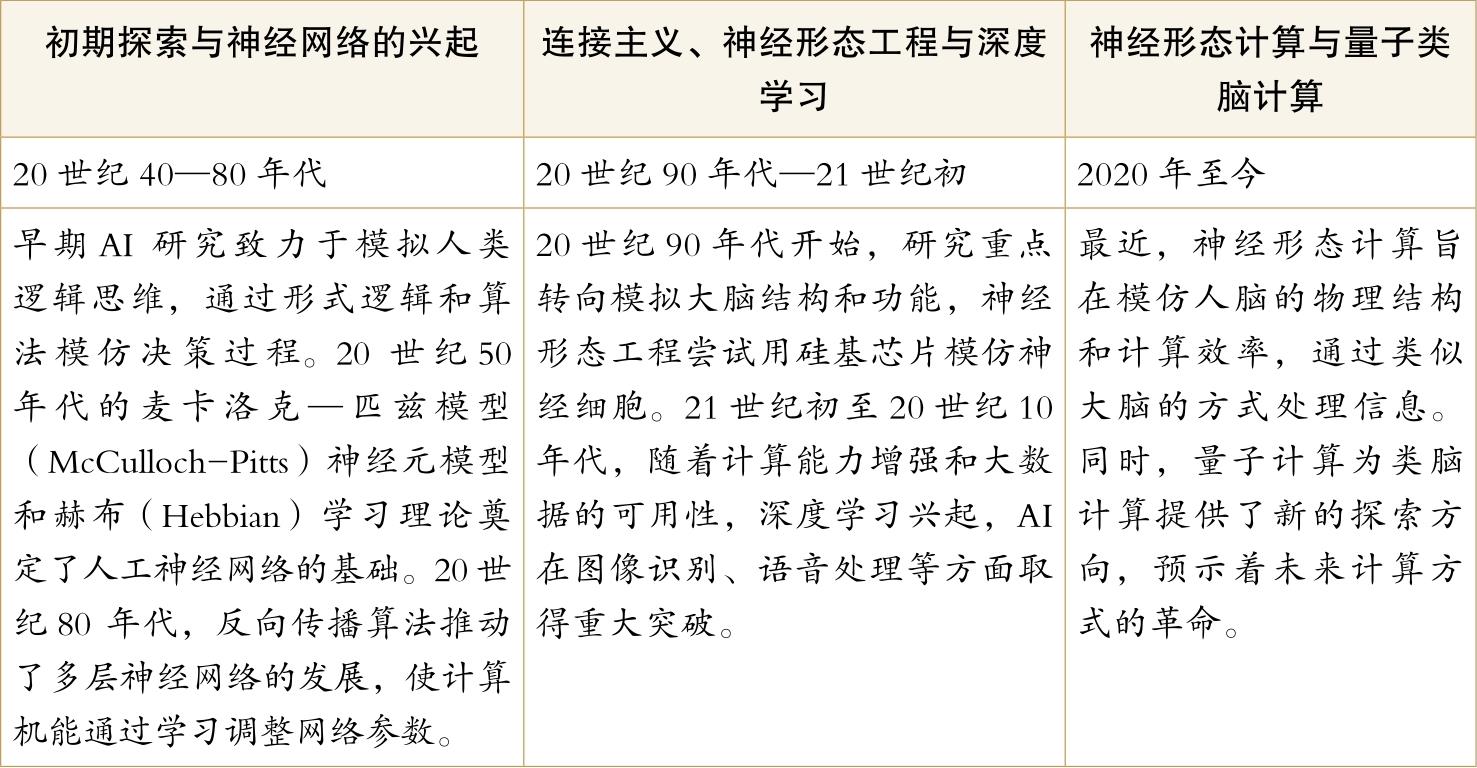
随着新技术的不断发展,未来的人工智能将在更广泛的领域实现更深层次的思考能力。这些高级人工智能系统不仅能模拟人脑的思考模式,还将超越人类,以前所未有的速度和广度解决复杂问题。

人工智能大脑智慧的发展阶段
◆大脑VS人工智能
简单来说,大脑和人工智能在几个方面有大比拼:
在神经元数量上, 大脑拥有约1000亿个神经元。然而,随着ChatGPT等AI模型的出现,AI的规模已扩展至3000亿甚至数万亿,数量上似乎已超越了人类大脑。 在能源消耗上 ,大脑在能源效率上胜出。比如,Frontier超级计算机虽然很强大,但它的能源消耗是大脑的100万倍。同时,大脑还有惊人的存储能力,大约2500 TB。 在信息处理方式上 ,大脑的多区域并行处理能力,与神经网络的层级顺序激活形成鲜明对比。但这并不意味着AI无法在未来迎头赶上。 在运算速度上, AI则以每秒约100亿次的运算能力,远超大脑神经元不超过1000次的激活频率。这意味着在处理大数据决策时,AI能够更快、更准确地完成任务。
当Marc Andreessen在2011年抛出“软件将吞噬世界”的预言时,他或许未曾预见到人工智能的崛起将赋予这一预言更深远的意义。如今,人工智能作为这一领域的新星,正以其独特的光芒照亮编程的门槛,让更多非专业人士得以窥见软件开发的奥秘。黄仁勋(Jensen Huang),英伟达的掌舵者,以其敏锐的洞察力捕捉到了这一趋势,他提出“AI将吞噬软件”,这不仅是对现状的精准描述,更是对未来的大胆预言。人工智能在解析复杂业务问题和编写分析代码方面展现出了惊人的能力,它正逐步替代人类,成为数据分析领域的新宠。
当我们谈论人工智能大脑时,其独特之处在于它的独立创造力和“智慧”——这曾是人类的专利。然而,尽管AI拥有巨大潜力,我们在应用过程中必须仔细界定目标和限制,并持续监督其学习过程,以确保其行为符合我们的意图和社会的道德标准,从而为人类社会带来真正的价值。
(二)看:眼观六路的视觉能力
今天,我们不再满足于自然界赋予的视觉能力。好奇心驱使我们创造机器,希望其视觉能力至少和我们一样,甚至更好。机器视觉(Machine Vision)是模拟人类视觉系统对外界环境的感知、识别和理解的能力。
人工智能中机器视觉的发展历程是一段充满创新和突破的历史。
人工智能中机器视觉的发展阶段

如上表所示,计算机视觉主要经历了三个发展阶段。伴随着同期互联网海量数据的爆发,各类数据集成为计算机视觉技术发展的土壤,而深度学习和深层神经网络理论最终带来最新一次的技术变革。自2010年起,ImageNet大规模视觉识别挑战赛(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)便如同一股强劲的东风,推动了深度学习在图像识别领域的迅猛发展。2015 年,一场具有里程碑意义的竞赛中,ResNet(Residual Neural Network,残差神经网络)模型以3.57%的识别错误率,首次超越了人类视觉系统的5.1%,书写了人工智能的新篇章。如今,人脸识别技术更是突飞猛进,准确率已飙升至97%以上,标志着人工智能在视觉识别领域的卓越成就。
视觉的全新方向,空间智能让看变成了理解,理解导致了行动 。在李飞飞的TED演讲中,她描绘了“空间智能”的奇妙图景,这不仅是视觉的感知,更是对环境的深刻理解和行动的指导。如同我们在街头漫步,不只是简单地观察,而是在不断学习如何与周围世界互动。现在,我们正试图将这种天赋能力赋予机器。
如下图所示,想象一下当大脑捕捉到一个杯子的影像时,它不只是识别出它的形状,而是理解它在空间中的位置,与周围物体的关系,甚至预测可能发生的事件。这就是空间智能的神奇之处。

空间智能
科学家们正在将这种能力赋予机器。从谷歌的3D空间算法,到斯坦福的无限空间生成技术,再到医疗安全领域的智能应用,空间智能正在不断拓展机器的潜能。随着空间智能的发展,我们正步入一个新时代。在这个时代,机器不仅能看,还能理解,甚至行动,开启了机器学习的新篇章。
(三)听:耳听八方的识别能力
我们都知道,人与智能机械的交互可以通过多种方式,比如文字、动作、声音等等。其中,“声音”这种方式对于人来说是最省力的,也是一种不可替代的交互方式。机器要能通过“声音”的方式与人交互,就需要识别出人说的话的内容。语音识别便是将声音转换为文字的过程。
如下表所示,语音识别技术发展经历了三个阶段,实现从理论模型到实际应用的突破。
语音识别技术的发展阶段

随着科技的飞速发展,语音识别技术已经渗透到我们生活的方方面面,成为我们日常不可或缺的助手。智能助手如苹果的Siri、亚马逊的Alexa和谷歌的Google Assistant,不仅简化了打电话、发短信等日常任务,还通过控制智能家居、播放音乐等提升了生活的便捷性。在文字转换领域,谷歌的Google Docs语音输入和Otter.ai等应用,为会议记录和讲座转录带来了革命性的便利。这些工具能实时将语音转化为文字,提高了记录效率,也便于存档和检索,广泛应用于商务和教育。
语音识别技术正乘着创新的翅膀,从传统的训练方法迈向神经网络的端到端模式,实现了准确性的飞跃。然而,这场技术革命远未画上句号,它仍需在自然语言理解、语音合成等领域继续深耕。同时,在AI技术日益普及的今天,开放性成为推动技术发展的关键。通过技术共享,可以缩小不同厂商之间的差距,吸引更多用户,共同推动整个生态系统的繁荣。
(四)说:情绪表达的输出能力
沟通不仅仅是信息的交换,它还蕴含着情感的流转。随着人工智能的发展,我们现在有能力将这种情感的细腻流动植入到机器的语言之中。特别是通过文本转语音(Text to Speech,TTS)和如Chatbot GPT-4这样的文本生成模型,AI的情绪表达已迈向一个新的高度。
如下表所示,人工智能输出的发展经历了三个阶段。
人工智能输出的发展阶段
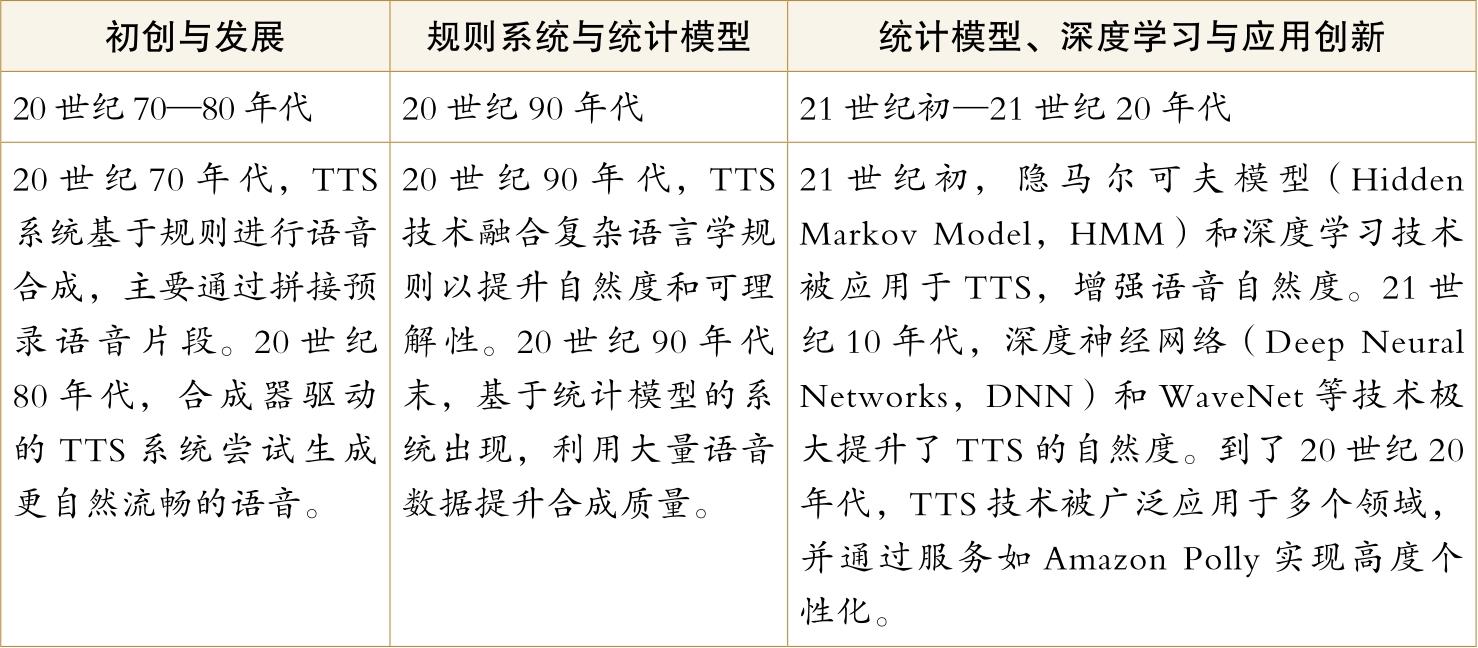
2024年春,OpenAI的GPT-4o以其语言理解、生成和实时音视频交互能力,成为技术界的焦点。这款AI模型以其人性化对话、即时反馈和情绪感知,重塑了人机互动,影响了多个行业。未来,TTS技术将更加注重个性化和情感的真实传达,同时,提升其处理多元语言和方言的能力,以增强模型的泛化性。随着技术的不断演进,TTS系统将以其日益提升的自然度和准确性,在虚拟助手、自动客服、语言学习、有声读物制作等多个领域大放异彩。这不仅是技术的飞跃,更是人类与机器沟通方式的革新。
(五)读:理解信息的阅读能力
在这个信息爆炸的时代,我们被各式各样的数据与文字所环绕,如何从中迅速且准确地提取有价值的信息已成为科技发展的一项重要任务。在这样的背景下,光学字符识别(Optical Character Recognition,OCR)技术应运而生,利用计算机和光学技术将图片中的文字信息,转换成计算机可以理解和识别的文字,并逐步成为我们进行智慧阅读的得力助手。
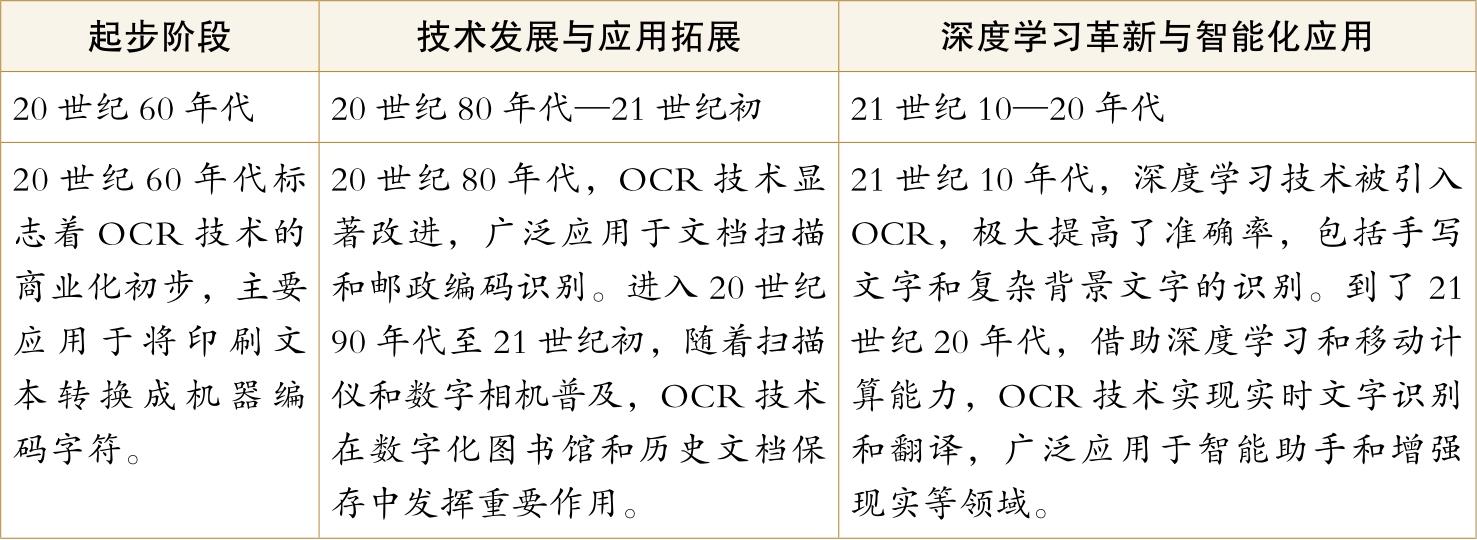
如下表所示,人工智能阅读能力的提升经过了三个阶段。
人工智能阅读能力的发展阶段
(六)写:写字绘画的创作能力
AI模型可以根据处理的数据类型数量分为单模态和多模态两大类。单模态模型专注于文本、音频或图像中的一种;而多模态模型则能够驾驭两种或更多类型的数据。
单一模态的大模型的发展历程如下表所示:
单一模态的大模型的发展阶段

多模态大模型的发展历程如下表所示:
多模态大模型的发展阶段

2023年2月,ChatGPT让OpenAI一炮而红,在发布后的五天内就吸引了超过百万的用户,而在仅仅两个月的时间内,ChatGPT的月活跃用户数就达到了1亿。相比之下,TikTok用了9个月时间才达到1亿月活用户,Instagram用了两年半的时间。在这个后疫情时代,ChatGPT如同一颗璀璨的新星,以其科技属性、流量纪录和资本追逐,编织成了绝佳的故事脚本。科技圈和创投圈的躁动,在股市相关概念的一片飘红中得到了验证。
“技术爆炸”这个词,《三体》的粉丝一定不陌生。而在ChatGPT问世后,这一概念被赋予了新的意义。从供给侧到需求侧,从业界到普罗大众,ChatGPT掀起了一场应用和再创造的狂潮。微软首席执行官萨蒂亚·纳德拉(Satya Nadella)感叹道:“我从未见过,至少在我从事科技行业的30年中,发生在美国西海岸的先进科技在几个月内就能出现在印度农村的某个人身上。”这正是技术扩散的奇迹。短短两个月,人们便挖掘出ChatGPT的各种技能,包括写代码、作业、论文,甚至家装设计和人生规划建议。
中国科技界针对大模型目前也形成了两种截然不同的态度: 一派是技术信仰派,他们坚信着人工通用智能(Artificial General Intelligence,AGI)的圣杯,以及规模定律(Scaling Law)的力量。Scaling Law的基本原理是,随着模型规模的增加,模型的性能也会相应提高。他们的思想深受硅谷创新精神的熏陶,认为技术的进步将带来应用的无限可能。在他们看来,只有不断追求更庞大、更强大的AI能力,才能在模型能力的飞跃中,稳固自己的阵地,不被他人超越。另一派则是市场信仰派,他们深信技术的迅猛增长终将放缓,而关键在于将适量的AI能力投入到能够迅速带来收益的商业场景中。他们依托着中国市场的庞大与独特,用数据的力量构筑起坚固的壁垒。这些人往往在中国竞争激烈的商业环境中历练已久,思想更贴近本土的土壤。
两派之间的根本分歧,在于对开源模型未来的预测。技术信仰派坚信,开源模型永远无法缩短与闭源模型之间的鸿沟,甚至这一差距将日益扩大。而市场信仰派则乐观地认为,开源模型终将迎头赶上,甚至超越。
(七)做:人工智能的承载形态
物理侧的具身智能通过仿生结构、先进传感器和智能算法,使机械体在现实世界中灵动如人,胜任家庭、工业、医疗和救援等多领域任务;而虚拟侧的人工智能体(AI Agent)则以数字形态承载人类智慧,从虚拟助手到自动化决策系统,涵盖服务、教育、娱乐等方方面面,成为人类生活中无形却不可或缺的伙伴。
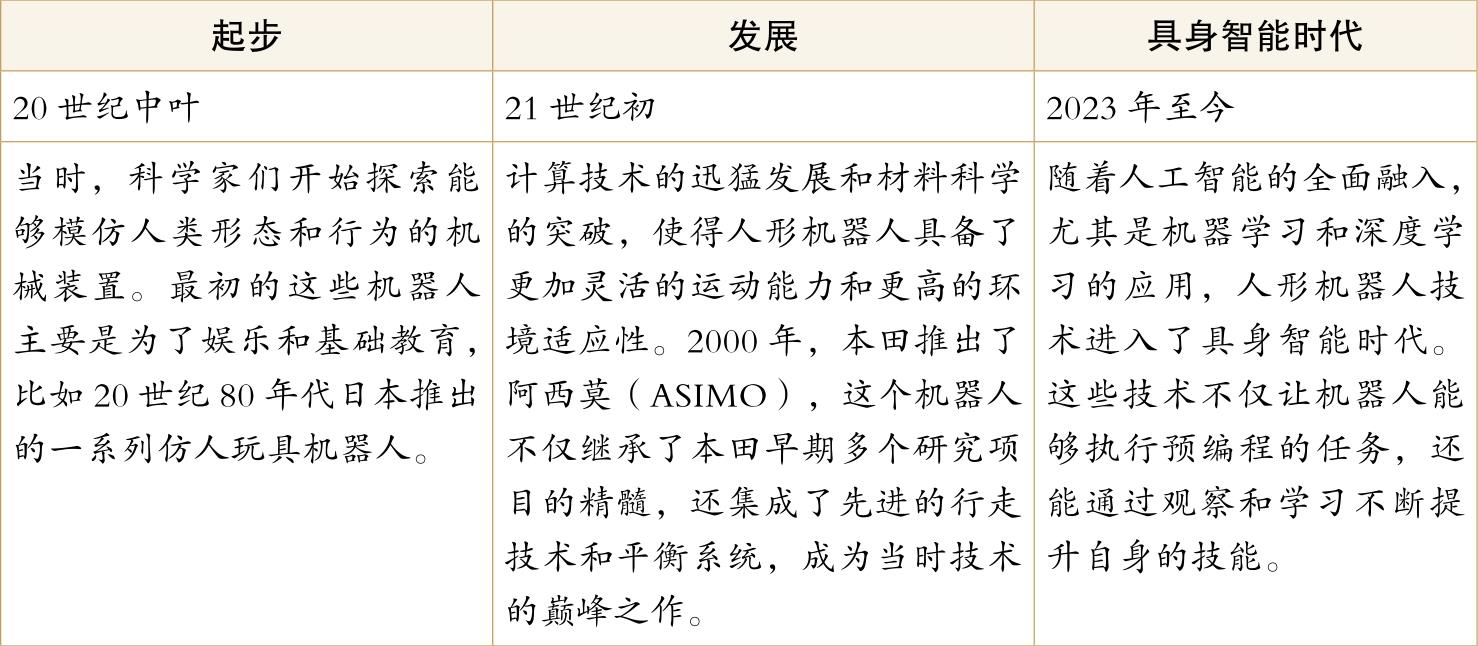
人形机器人的发展如今已步入具身智能时代,如下表所示:
人形机器人的发展阶段
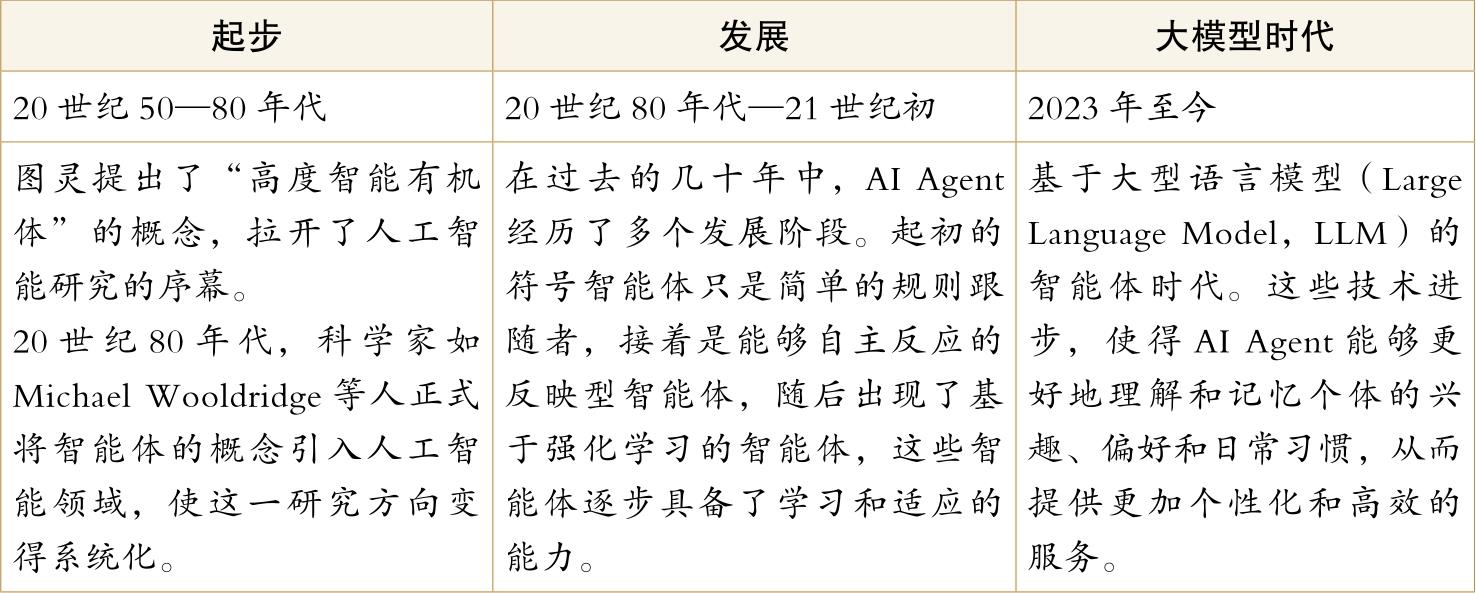
AI Agent逐步发展至大模型时代,如下表所示:
AI Agent的发展阶段
关于人形机器人的商业化落地,业内一般认为,未来3到5年将是人形机器人逐渐渗透到各个产业并寻找适用场景的时期,而5到10年后,人形机器人才可能迎来大规模的商业应用。
在商业化落地的过程中,会遇到一些阻碍,其中真实场景数据的不足是人形机器人开发和迭代面临的最大挑战。目前人形机器人尚未达到让广大消费者愿意为其数据收集过程付费的阶段,因此,仿真数据训练成为其中可选的一种手段,即利用计算机模拟真实场景来生成训练数据。未来只有当足够多的人形机器人在真实场景中得到应用,才能形成有效的数据闭环。
另外,产业界也有相关人员认为,短期内限制人形机器人落地的主要因素是硬件技术。目前人形机器人的移动和操作精度尚未达到高精度水平,这导致了收集到的数据可用性较差。例如,人形机器人上肢的抓取精度仍然在10厘米左右,与工业机器人0.01毫米的精度相差甚远。因此,即便收集了大量数据,也只有少数几条能够用于训练,数据闭环的形成可能比预期的要慢。
而AI Agent方面,2024年伊始,人工智能的巨头们都在忙着升级自己的技术,特别是让AI能够更好地理解和处理文字和图片等多种形式的信息。像Gemini 1.5 Pro、Claude 3、GPT-4o和Kimi这样的智能助手,都在处理长篇文章和多种信息方面有了很大进步,这标志着AI Agent技术到了新的拐点。以前,AI Agent在处理多种信息时可能会比较缓慢,但现在原生的多模态技术让它们反应更快了。特别是OpenAI推出的GPT-4o,它通过一种全新的训练方式,能够同时处理文字、图片等多种信息,显示出AI在实际应用中的潜力。
为了避免所有的AI Agent都变得千篇一律,支持它们完成复杂的长任务变得非常重要。长上下文,也就是让AI能够理解和记住更多的信息,是解决这个问题的关键。到了2024年初,这些AI模型在处理长篇文章方面的能力有了显著提升。通过改进它们的内部结构和注意力机制,AI Agent在记忆长任务方面做得更好了,这为它们提供了更强大的基础能力。
然而,AI Agent现在面临的一个重要问题是如何控制成本。随着AI Agent需要处理的信息越来越多,它们在计算和存储上的成本也随之增加。增加信息处理的深度,比如让AI Agent记住更多的上下文信息,会让计算成本大幅度上升。
想象一下,如果一个AI Agent每天和用户聊天一个小时,一个月下来就会产生45万个信息单元(Tokens)。这对大多数AI模型来说,已经超出了它们能处理的范围。即使是能够处理这么多信息的高级模型,比如GPT-4 Turbo,它的成本也是相当高的。比如,输出1000个信息单元的成本可能高达0.03美元,这对大多数用户来说太贵了。只有在一些特殊的商业应用或者高价值的个人服务中,比如AI心理咨询或者在线教育,使用这样的高级模型才可能实现收支平衡。相比之下,从成本效益更高的模型,比如GPT-3.5开始构建AI Agent,可能是一个更经济的选择。
因此,一种可能的解决方案是使用类似于混合专家模型(Mixture of Experts,MoE)的路由技术。这种方法可以根据问题的复杂性,将简单的问题交给简单的模型处理,复杂的问题交给复杂的模型处理,从而有效降低成本。这样,AI Agent既能提供高质量的服务,又能控制成本,使其更加实用和普及。

