第二章
了解数据图的原理:深入大脑
数据图是数据沟通的一种关键工具。有些关系太复杂了,只用数字表示的话很难让人理解,而数据图能够使其一目了然。即便是最复杂的数据图,也是在利用人类视觉感知系统的几点特征。本章会讲解受众解码数据图信息的方式。第一节介绍视觉感知的基本特征。第二节讨论高效设计需要考虑的前注意特征(preattentive attributes)与格式塔原理。如果掌握了这些概念,你的受众就能轻松且可靠地解码你制作的数据图。章末习题是拆解一张数据图,让你能够将上述两节融会贯通。
我们如何解码数据图
数据图发挥威力的根源是,视觉加工系统很擅长发现视觉要素之间的关系。看看周围,注意你确定视野内每个物体的大小远近是多么快,多么轻松。这是因为,人类有能力处理所见物体的大小和位置。你的大脑刚刚绘制了一幅连贯的三维环境图,而你丝毫感受不到认知负荷。
人脑对上述视觉信息进行过滤,形成连贯图景的一种途径,就是将信息分块。闭上眼睛,你大概记不得你刚刚见过的所有事物的全貌。大脑记住的是信息块:凌乱的书桌、窗外的树、书架。同理,高效数据图要对信息进行符合逻辑的分块处理,减轻受众的认知负荷。
大脑的另一种过滤方式是,聚焦于突出的或异样的事物。这种视觉性质叫作 突出性 。突出的视觉要素会留在脑海中。你在林间漫步,周围有几百棵树,而大脑会倾向于看见那一棵有响动的树——树后面可能有一头熊。个别树的响动是非常突出的。突出性是人脑限制认知负荷的一个例子。在同一时间,最突出的要素只会有一个。
数据图利用上述原理,将数量信息进行可视化编码,并将数量关系呈现为一条或多条数轴上的关系。
 大脑几乎会瞬间发现图中要素之间的视觉关系,将信息分块,识别最突出的元素。因为这个过程发生得很快,所以我们要理解上述每一个概念在受众观看数据图时的反映形式。这是实现高效沟通的关键一步。
大脑几乎会瞬间发现图中要素之间的视觉关系,将信息分块,识别最突出的元素。因为这个过程发生得很快,所以我们要理解上述每一个概念在受众观看数据图时的反映形式。这是实现高效沟通的关键一步。
发现关系
数据图利用了我们的一种超能力,那就是迅速且轻易地发现视觉关系。统计学家弗朗西斯·安斯科姆(Francis Anscombe)给出了一个数据集,用以展现人类视觉系统的能力(以及数据集离群值的强烈影响),见表2.1。
表2.1 安斯科姆四重奏
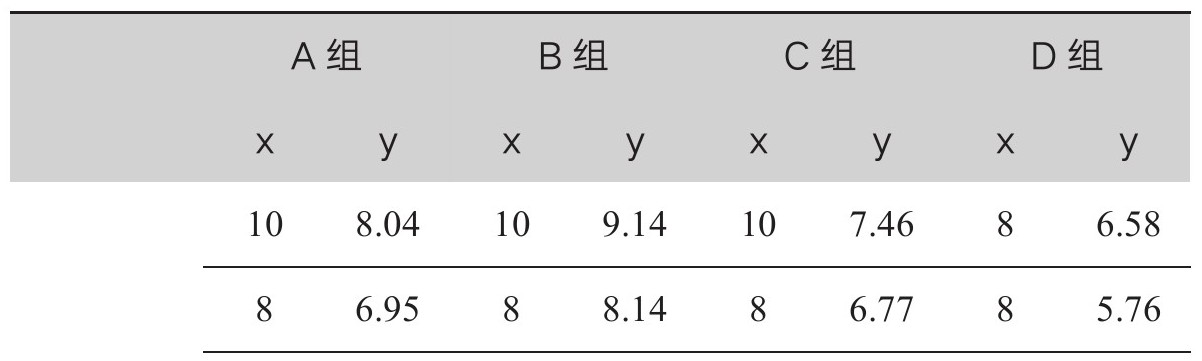
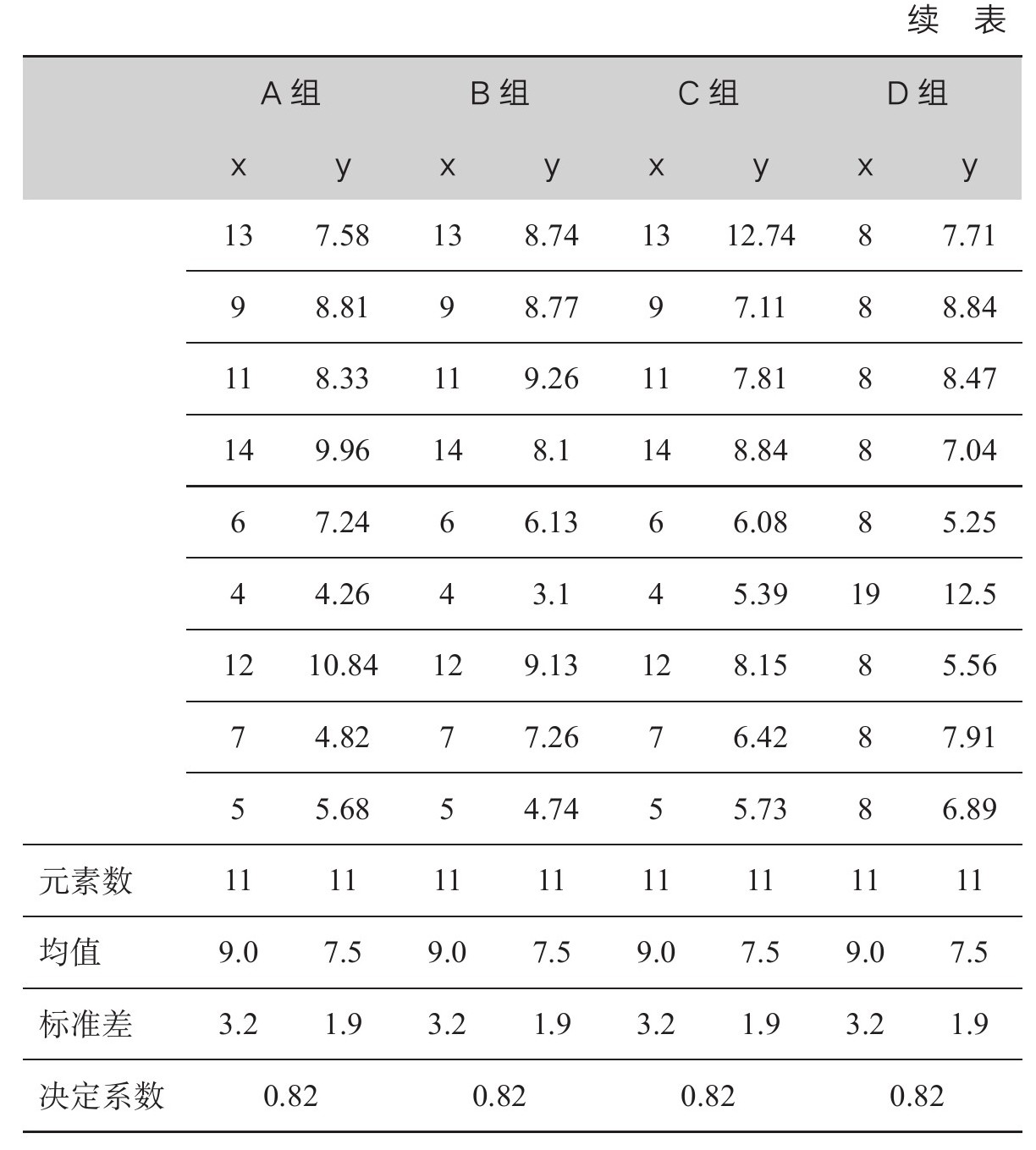
来源:F.J.Anscombe,“Graphs in Statistical Analysis,”American Statistician 27(Feb.1973):17-21。
从统计层面看,四组数据几乎相同。每一列的均值、标准差和元素数都一样。每组数据中x和y的相关系数都相同(精确到小数点后两位)。看一遍表格就会发现,数据组显然各不相同,但很少有人能迅速概括出差别。
再来看下面代表各组数据的数据图(图2.1)。相比于表格,数据图更清晰便捷地体现了四组数据的关系。通过这个例子,安斯科姆主张,视觉化是数据探索中的一个关键步骤。他想要反驳一种看法,即“数字计算是精确的,数据图是粗略的”。他的例子提醒我们,绘制数据图是为了呈现关系。如果不呈现关系,数据图这个工具就没用。如果要呈现关系,受众理解数据图的速度和便利度可能会优于观看数据表。
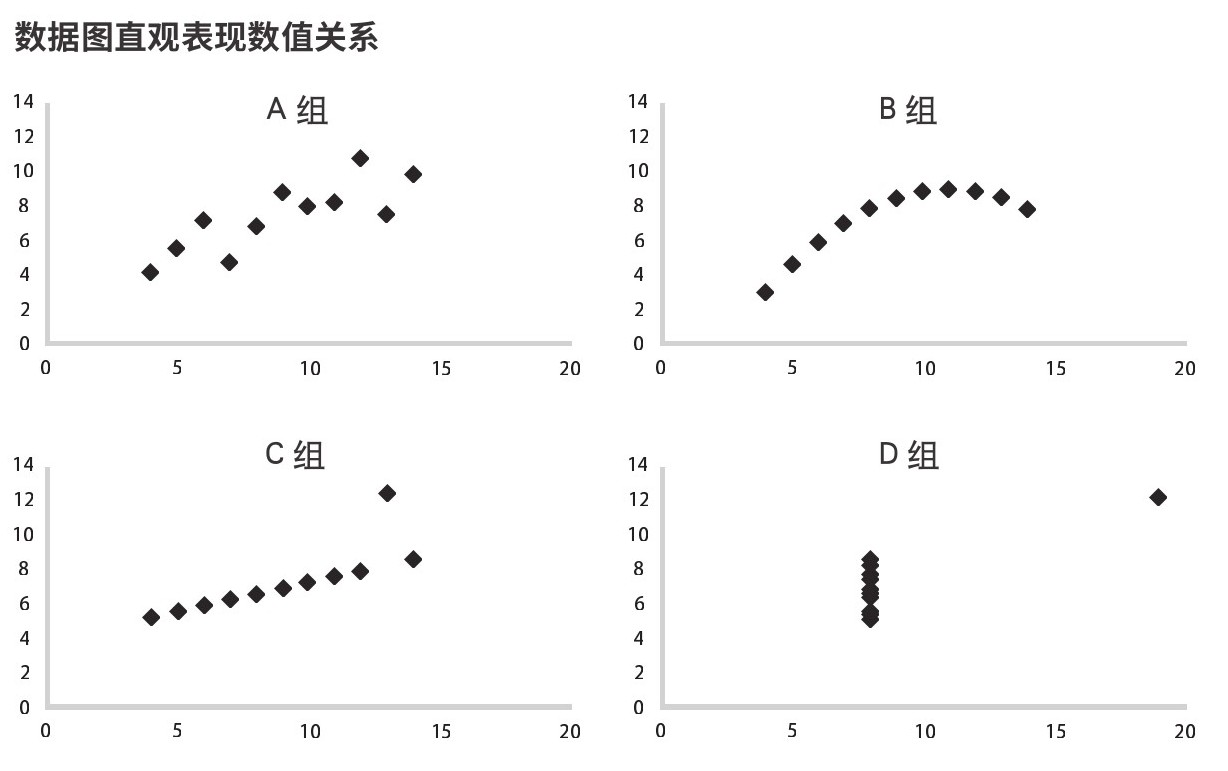
图2.1 表2.1对应数据图
来源:F.J.Anscombe,“Graphs in Statistical Analysis,”American Statistician 27(Feb.1973):17-21。
发现数据块
大脑会将输入的信息分块。
块可以是概念或符号的任意组合。块之所以是块,是因为我们能够将它识别为单个概念。要画好数据图,就要选择数据分块的方式。
块的划分标准是灵活的。几乎任何一组观念或意象都可以纳入一个块里,具体取决于我们内心的划分方式。然而,同一时间内能够主动处理的块数有严格限制。一般来说,我们一次能够处理三到四个块。
借助数据图,你可以将大量数据点整合成一个方便回忆的图块。在表2.2中,大部分人会把每个数字当作一个独立的块。他们或许能记住四个极值,表中对其做了强调处理。
表2.2 报修次数(前一年)
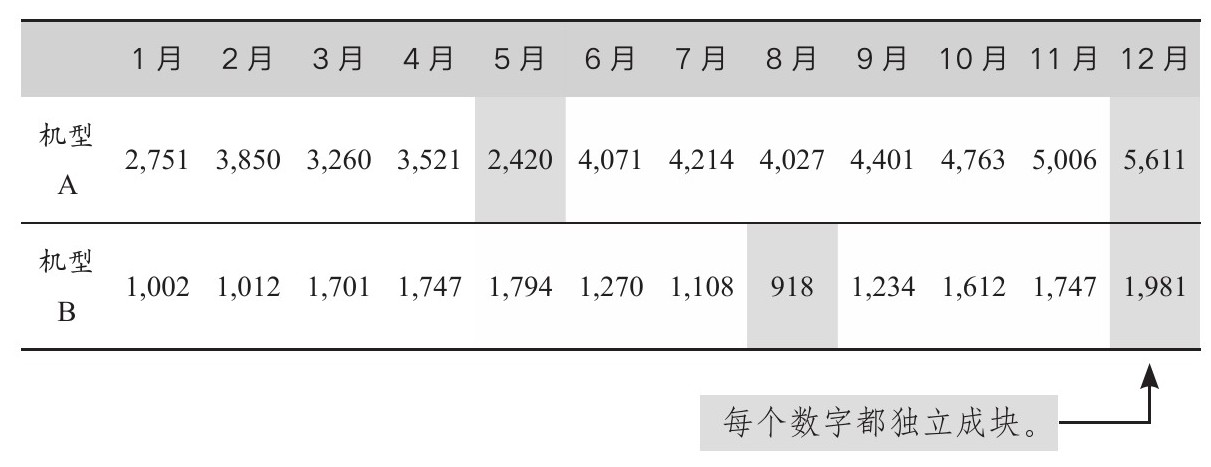
如图2.2所示,折线图将这24个数字分成了两个块:机型A是一条折线,机型B是另一条折线。分好块后,每块的模式和两块之间的关系就更容易辨别和记忆了。数据可视化就是要进行适当分块,便于发现主要关系。
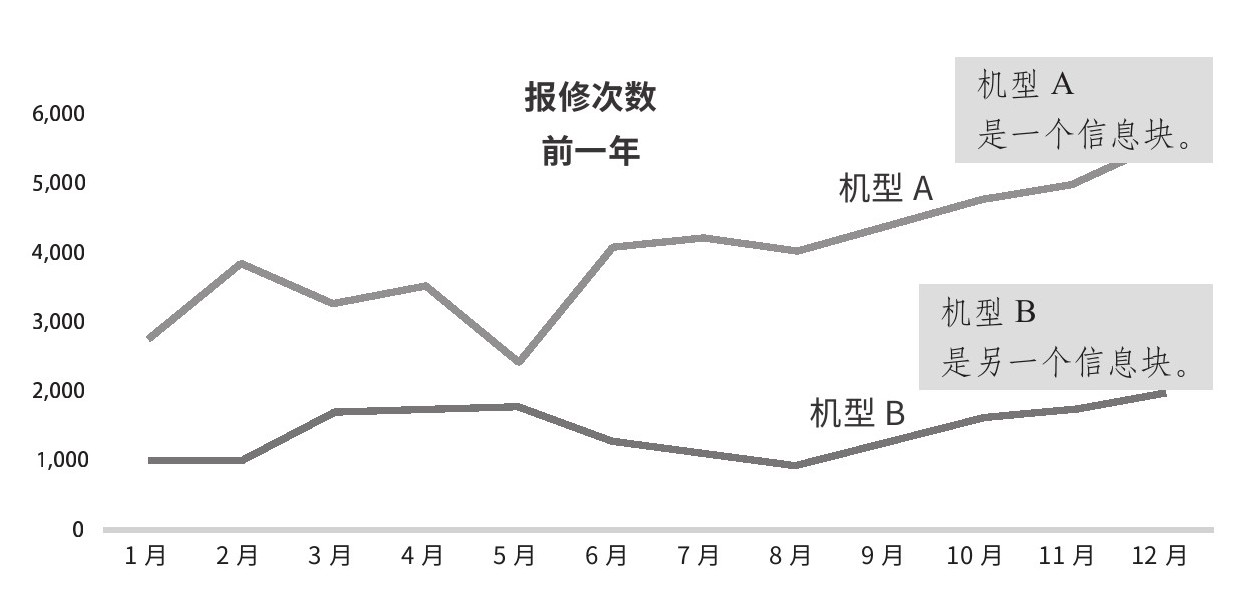
图2.2 报修次数
来源:改编自斯蒂芬·菲尤(Stephen Few)的《数据可视化实战》(Now You See it),2009。
发现最突出的要素
我们过滤信息的能力与发现关系的能力一样强大。人脑不会为进入眼睛的每一束光线赋予相同权重,而会聚焦于突出的部分。如果没有突出点,受众可能就无法聚焦于主要关系,理解关系的含义。要懂得突出性,确保受众将注意力放在正确的位置上,确保每一个解释性数据图都有一个最突出的点。
我们来看下面这组数字,其中每个数字都有相等的视觉突出性。现在请你数一数图2.3中有多少个数字6,注意你用了多长时间。

图2.3 一组数字(1)
答案是四个,但你大概费了几秒钟才全部找到。现在重试一次。这一次的数表有了两个变化,让数字6更加突出,如图2.4所示。

图2.4 一组数字(2)
大多数人发现,在后一个数表中数6要容易得多,尽管排序并无变化。这是因为6的视觉效果比周围其他数字突出得多,颜色不一样,还做了加粗处理。周围数字从原来的黑色换成了对比度较低的浅灰色。这些都提高了数字6的突出性。我们的眼睛之所以会被突出元素吸引,是因为发现辨别视觉突出要素的认知负荷比较少。请注意,突出多个数字会消除这一效果。都突出,就都不突出了,如图2.5所示。
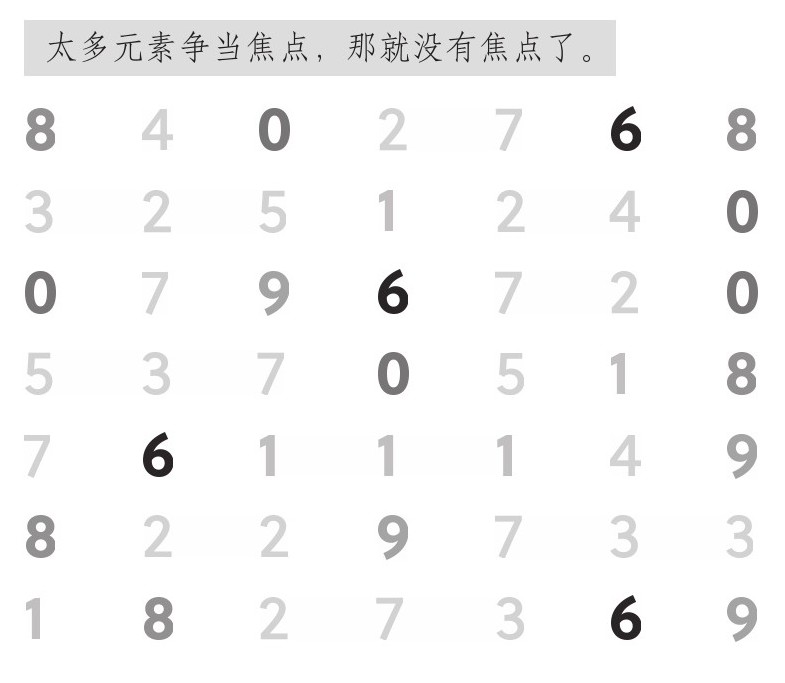
图2.5 一组数字(3)
来源:改编自科尔·努斯鲍默·纳福利克的《用数据讲故事》,2015。
要是将太多元素推到前台,受众的认知负荷就会加重,更难聚焦于任何一个元素。所有要素都突出的话,那就全都是噪声了。在知识诅咒的作用下,沟通者可能会对此视而不见。既然你已经知道了自己要找什么,那么,就算关键元素在受众看来并不突出,你还是会觉得它们很突出。
虽然我们不能控制别人的眼球,但我们可以影响哪些元素更突出,更可能引来关注。高效的数据沟通者会有意识地选择突出元素,以便应对多元认知的挑战。他们会将受众从噪声上引开,引向有意义的模式。为此,他们会认真和批判性地思考数据图的编码方式。
数据图如何编码数据
高效数据图利用人类的视觉加工系统,通过呈现数据关系,将数据点整合成数量较少的几个块,并通过确保同一时间内只有一个块突出,让受众的注意力聚焦到这个块上。
在抽象过程发生前,大脑必须先从眼睛看到的景象中创造出意义。这个过程的速度很快,不等受众将注意力投向数据图之前,它就已经完成了。这个过程叫作前注意加工。
借助高效的数据图,受众得以在低认知负荷下快速处理复杂信息,因为数据图利用了我们在前注意加工阶段中识别出的特征。关于大脑对视觉元素的组合方式,则是由格式塔原理负责。
前注意特征和格式塔原理解释了数据图何以有效。掌握了这方面的知识,你在制作数据图时就能做出更好的选择,让受众更快捷可靠地解码信息。
运用前注意特征编码数据
前注意特征是数据可视化的语法。数据图把数据拿过来,然后利用前注意特征对数据进行视觉编码。例如,柱形图借助的前注意特征是大小。柱越高,代表的数值越大。常见数据图利用了四个我们能够立即识别的前注意特征
,如图2.6所示。

图2.6 前注意特征示例
大小
由于自然界里有对等物,所以大小是最直观的编码。树的高度、宽度和体积编码了年龄。树越大,可能就越老。
大小是最常用的视觉编码。任何数值都可以通过高度、宽度或面积来编码。
在三者当中,高度一般是最容易用肉眼估测的,其次是宽度。至于面积差,受众就难以准确估计了,最多只能分辨出哪一块明显比另一块更大,如图2.7所示。

图2.7 尺寸编码示例
运用大小编码的最佳实践
柱形图的y轴要以0为原点
在可视化领域,例外的规矩不多,其中一条是:柱形图的y轴要以0为原点。y轴不以0为原点的做法叫作“截断y轴”,常常用于歪曲数据。在前注意阶段,我们估测高度差的能力实在太强了,以至于受众常常会不由自主地得出结论,哪怕图中标明了截断,如图2.8所示。
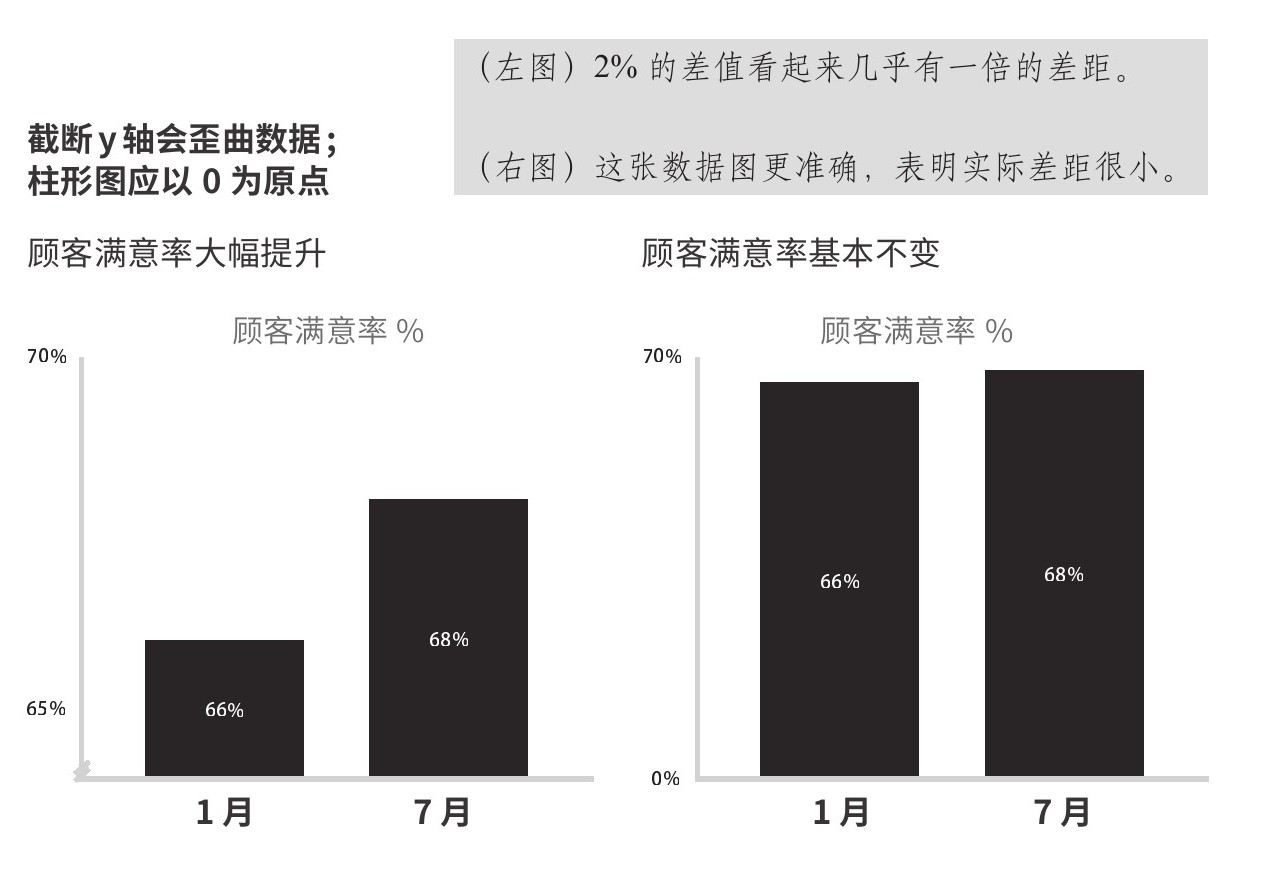
图2.8 顾客满意率
在图2.8左图中,y轴截断和误导性标题强化了错误的第一印象,即顾客满意度在1—7月间几乎翻了一番。虽然其实只增加了不到2%,但我们倾向于假定,柱高视差反映了背后数据的差异。
但有的时候,微小差别也是有意义的。对一家网络服务供应商来说,正常运行时间从99.9%降到99.5%,企业经营可能就会面临严重威胁。如果微小差别是有意义的,可以考虑采用反向统计量——比如故障时间——以强调变化幅度,或者不用柱形图,采用其他受众不太可能默认以0为基准线的数据图形式,如图2.9所示。
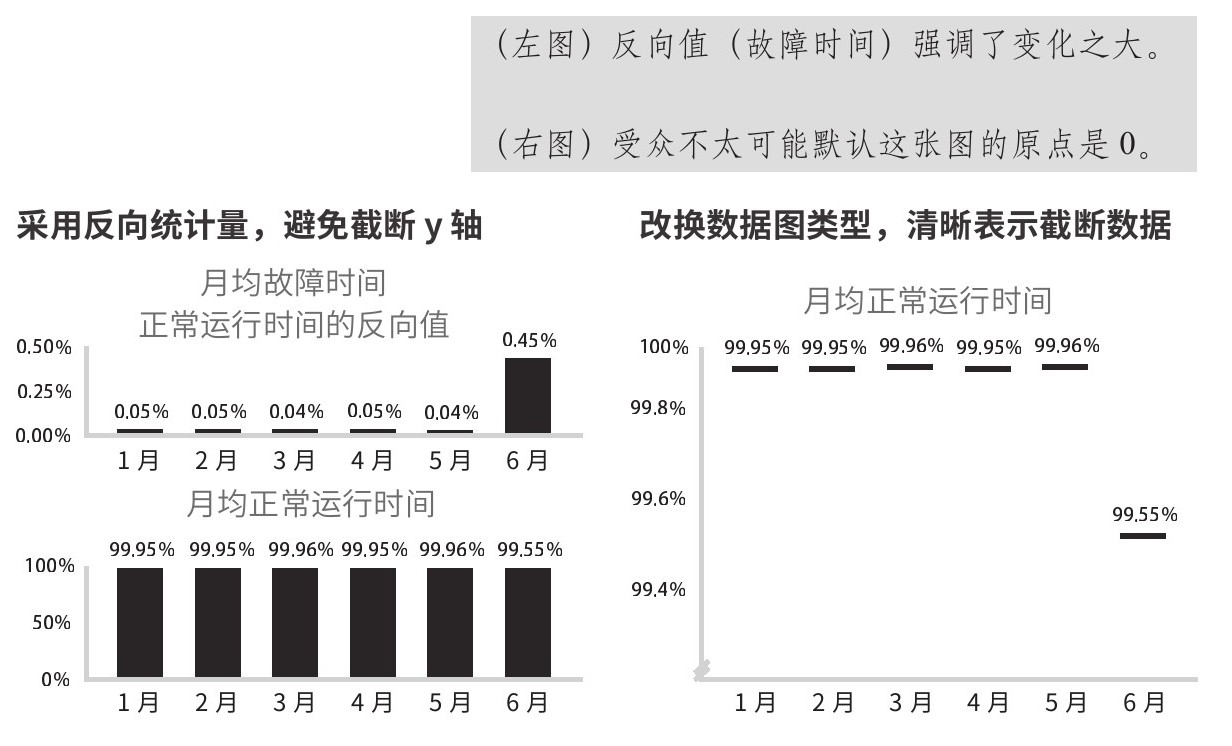
图2.9 运行情况
位 置
折线图和散点图是最常用的位置编码形式。数值可以通过纵向位置或横向位置编码,也可以像散点图那种兼用两种位置。一般来说,纵向位置高代表数值大。位置编码的三种形式如图2.10所示。

图2.10 位置编码示例
运用位置编码的最佳实践
请记住,受众默认以上为好
上方通常代表数值大,而对于营业收入、利润、顾客数等重要经营指标来说,数值越大越好。因此,受众一般会假定上好下差。
除非一个指标是受众成天见到的,否则在他们充分把握数据之前,你都应当假定他们会将上解读为好。尽可能遵守这一规范,以减轻受众的认知负担。在上代表坏的情况下,比如获客成本,请明确标示该数据的特殊性,见图2.11。
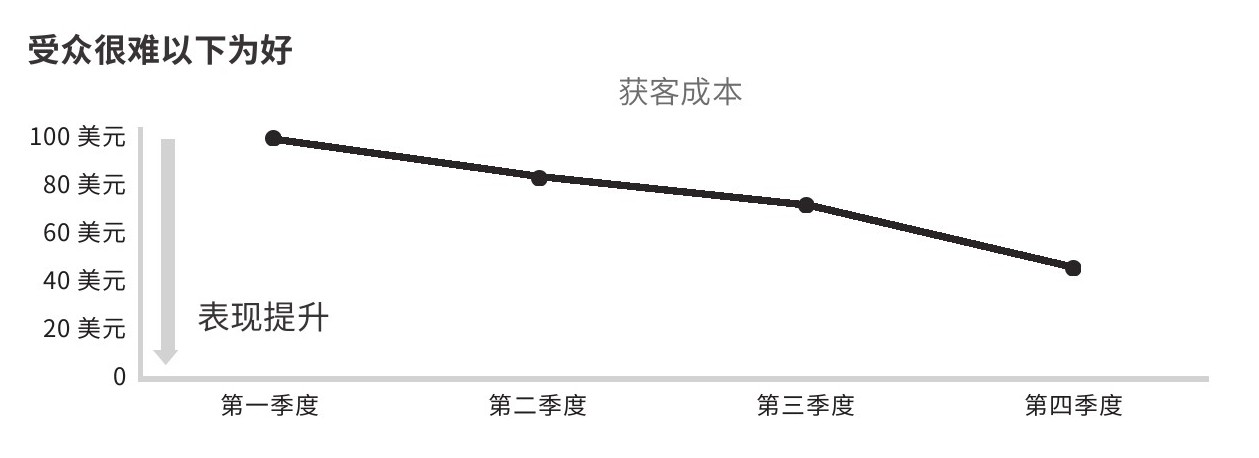
图2.11 获客成本
色 彩
在数据图中,用于意义编码的色彩有两种不同的前注意特征:色调和强度。
色调是我们通常所说的“颜色”的精确术语。不同于其他前注意特征,色调最适合进行类别和群组的编码,而非表示不同数值。
色彩的另一个维度——强度——既可以编码数值,也可以编码类别。
强度可以理解为颜色的透明度,因为在大多数常用的可视化程序中,最容易调整的参数就是透明度。强度为0时,颜色就和背景色相同。
一种常见的色调编码是用红色表示股价上涨,绿色代表股价下跌。一种常见的强度编码是用深浅不同的蓝色表示水深。蓝色越深,意味着水越深。
运用色彩编码的最佳实践
色调区分大类,强度区分小类
每个大类只用一种色调,大类下的小类用强度区分。图2.12中给出了三种用色调编码调研结果的不同方式,第一个最不直观,第三个最直观。
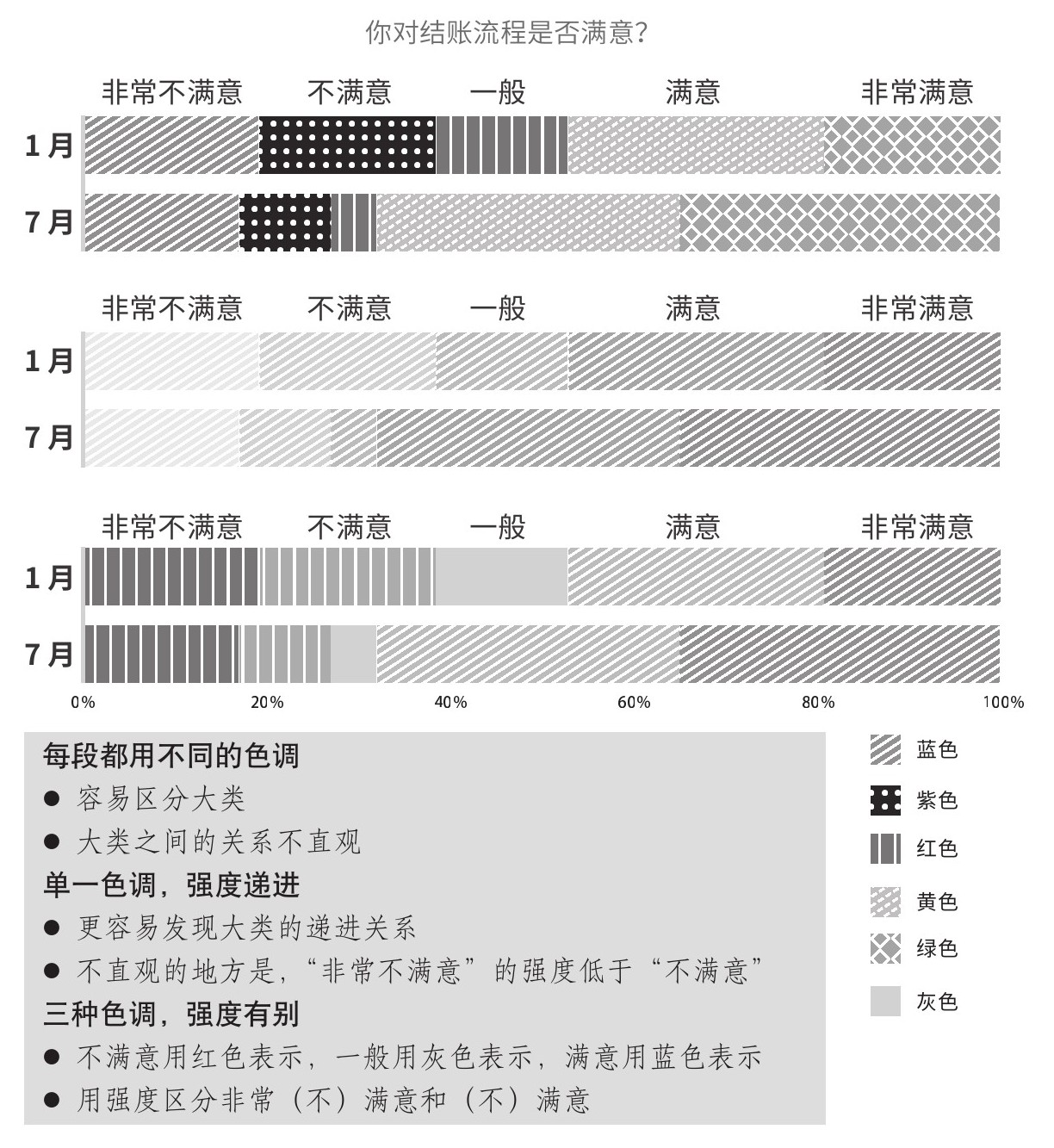
图2.12 三种色调编码方式
用强度突出大类下的元素
用强度来突出某个视觉元素,从而将受众的注意力聚焦到它上面。在图2.13右图中,区域4显得更突出,因为它采用了强度更高的黑色。如果讨论重点是区域4,那就要通过强度让受众聚焦到该区域。
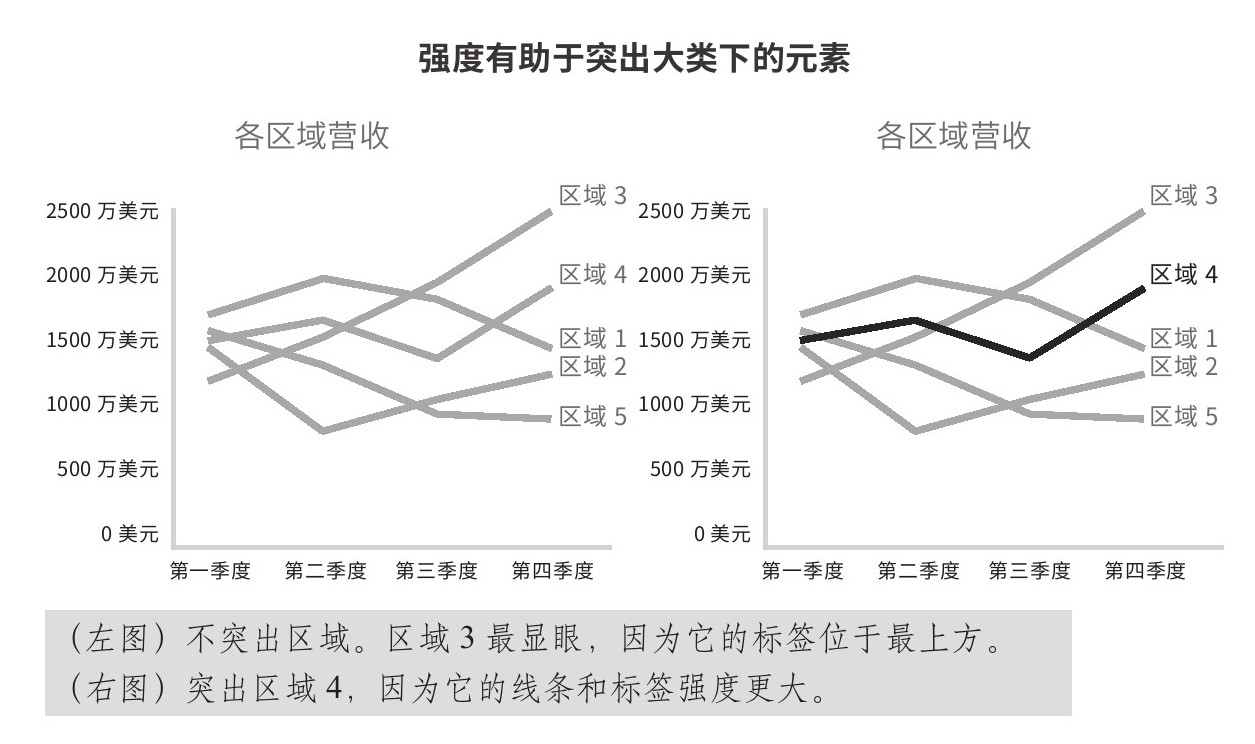
图2.13 强度的编码方式
用色不贪多
色调数量不能太多,以便减轻受众的认知负荷。在色调方面,知识的诅咒影响特别大。经过练习,人可以学会将多种不同颜色与不同类别对应起来。但面对不熟悉的颜色和类别,人们就很难快速解析了。因此,用色多对探索性数据可视化是有意义的,但在解释性可视化阶段是危险的。
规避色盲风险
如果受众超过20人的话,台下可能至少有一个人患有色觉障碍。要选择大多数受众都能区分的色调,查看黑白打印的呈现效果。要小心红绿组合和蓝绿组合,因为最常见的色觉障碍就是红绿色盲和蓝绿色盲。
考虑用强度来编码定量变量(不要用彩虹色)
定量变量要用强度来编码,不要用色调。另外,不要用彩虹色。尽管彩虹色在科学界内运用广泛,天气图中也常用,但学习难度大,不应用于解释性数据图。
用强度编码定量变量时,你要做出一个选择。是采用连续色轴,每个数值对应一个不同的强度,还是将数值分成几组,每组采用同一个强度。一般来说,连续色轴能更好地反映数据,除非语境要求用离散分组,比如考试分数(90—100分是A,80—89.9分是B)。见图2.14。

图2.14 强度编码数值的方式
运用格式塔原理创造意义
通过了解前注意特征,我们就能明白怎样用数据图对变量进行可视化编码。格式塔原理则是帮助我们理解受众对变量的解码方式,尤其是帮助我们预测受众会如何组合视觉元素。
格式塔原理源于20世纪德国心理学家的研究成果,他们试图解释我们今天所说的“分块”过程。
他们想要解释人脑建立视觉联系的原理。我们为什么会将虚线看成线条,而非一个个孤立的点?通过来自这些研究的原理,设计师可以开发出更符合直观的产品。你也可以将格式塔原理运用到数据图的选择中,让受众能够承受更低的认知负荷,进行更可靠的解码。
大部分数据图都利用四条核心格式塔原理,
如图2.15所示。
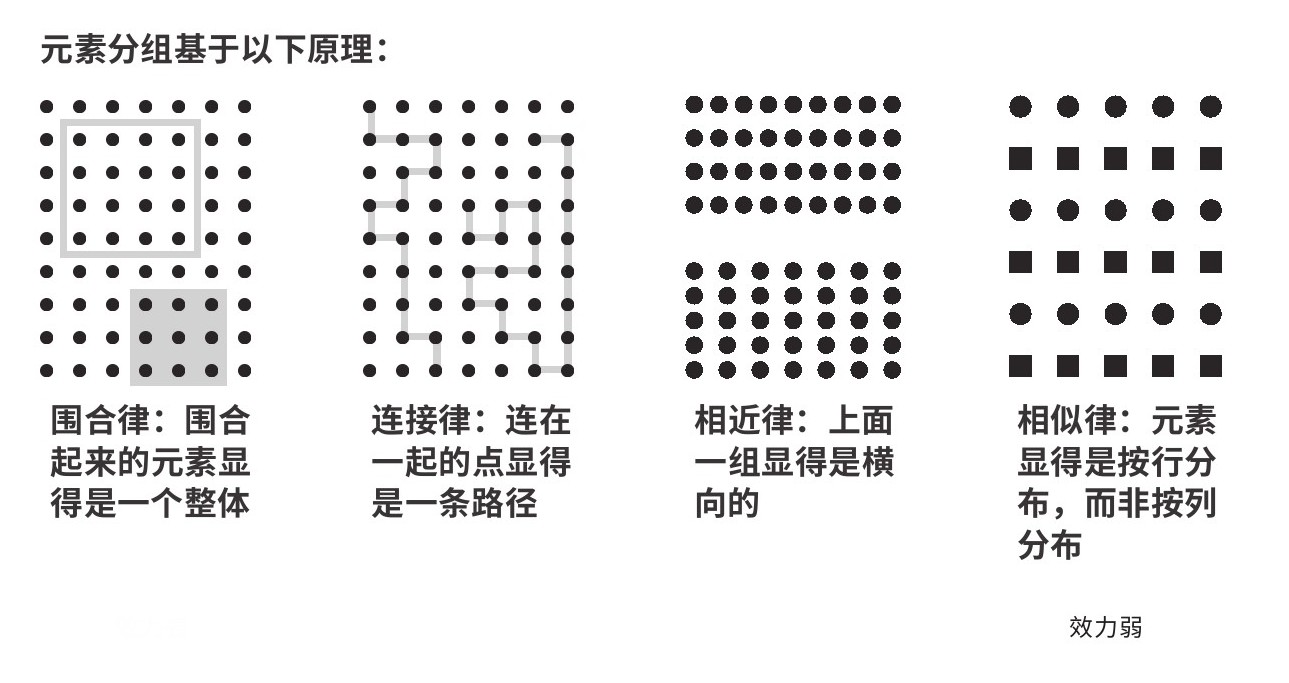
图2.15 元素分组原理
原理有主次
因为有些格式塔原理的视觉效果较强,所以通过对原理进行组合,变换不同元素的强度,我们就可以改变最突出的元素,影响受众的分块模式,如图2.16所示。

图2.16 不同原理组合的主次
例子中的每对图形都有一对圆形和一对三角形组成,圆形和三角形都有相同的形状和色调。大多数人看到最左边的一对时,都倾向于认为是纵向排列。圆形分成一块,三角形分成另一块。在中间的一对中,占据主导地位的格式塔原理是连接律。大部分人会认为是横向排列。圆形和三角形之间的连线压倒了相似律。在最右边的一对中,围合的圆形占据了主导地位,大多数人的注意力完全集中在两个圆形上。
对格式塔原理有了认识后,你应当小心运用。因为某些原理的效果太好,所以很多人喜欢用画圈和加粗的形式来凸显重点。你应当反其道而行之,采用爱德华·塔夫特(Edward Tufte)所说的“最小有效差”。要使用能达到期望效果的最弱原则,这样制作出来的数据图既能抓住受众,又不会让受众视觉过载。
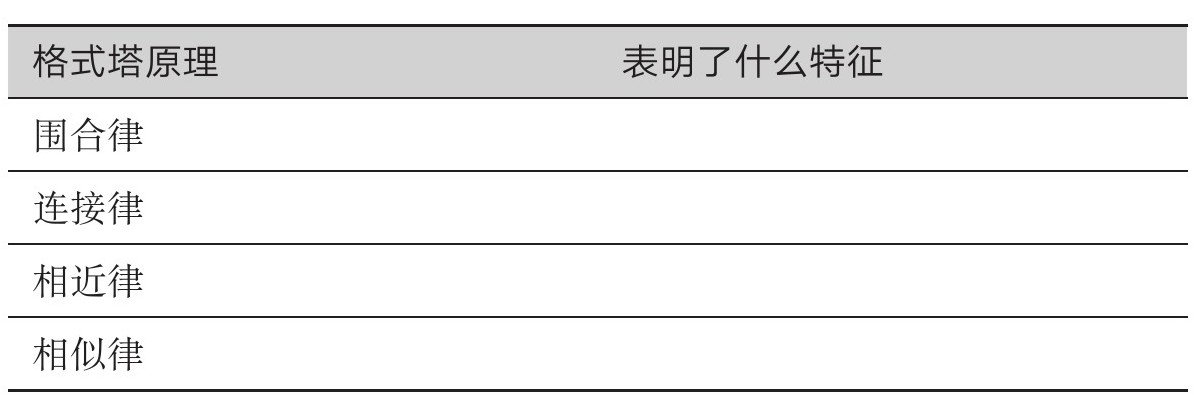
围合律
我们会将视觉上围合的元素当作一组。外框和区域涂色都是围合的例子。围合的效果很强。如果不需要围合就能起到强调效果,那就不要用围合。
运用围合律的最佳实践
用强度和色调代替围合来聚焦重点
围合是视觉效果最强的强调方式之一,容易将其他元素湮没,包括沟通者打算突出的元素在内。围合一般是上级领导改图时会用的,目的是在不重新画图的前提下,快速突出某个点。为了强调一个数据点,不一定要把它围合,可以考虑淡化其他元素,从而让关键数据显得更突出,如图2.17所示。
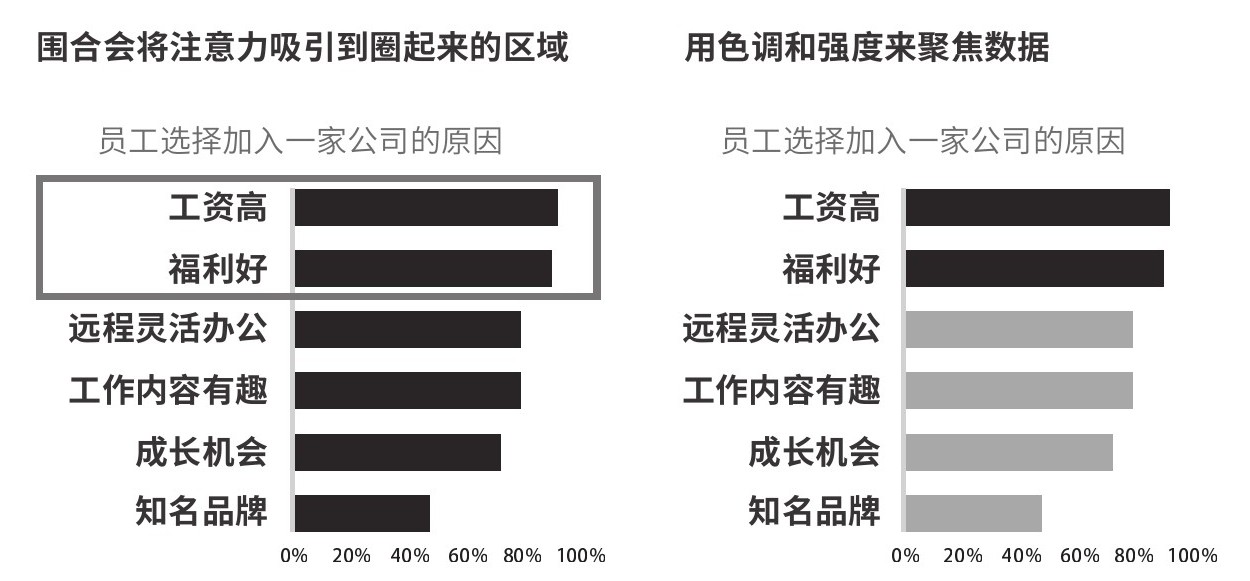
图2.17 两种方式的对比
分散围合分组
围合常用于分组,哪怕是分散使用,也能起到压倒性的效果。要忍住加方框或圆圈的诱惑,那会产生多个突出点,反而削弱每个点的效力。要按照重要程度建立信息层级,然后用不同的强度等级来表示信息层级,如图2.18所示。
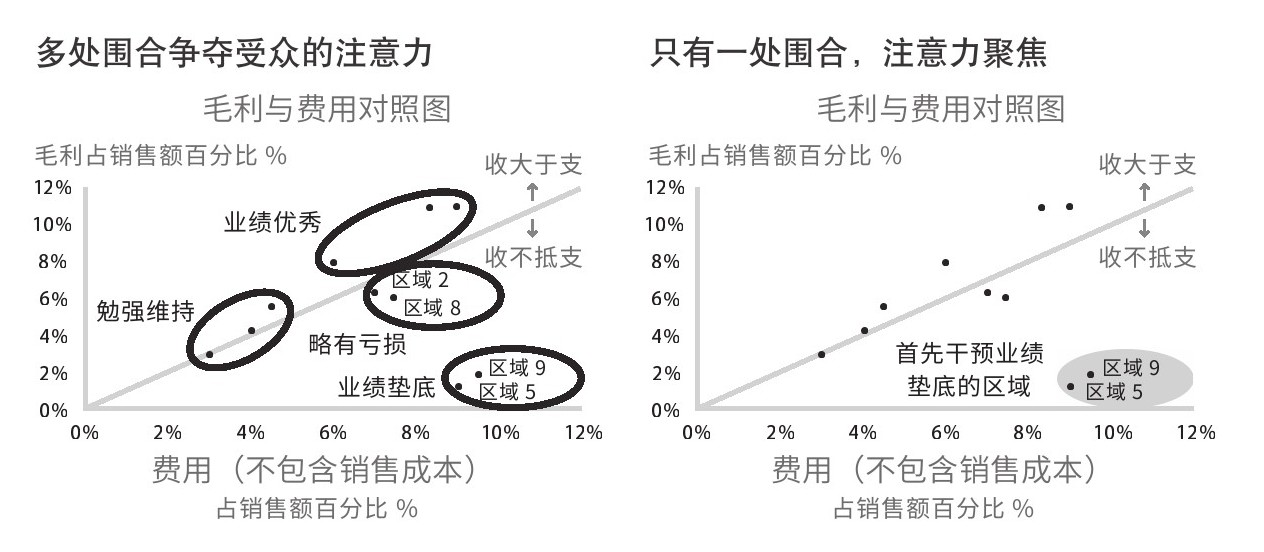
图2.18 多处围合与一处围合的对比
连接律
我们会将视觉上相连的元素当作一组。折线图就是利用了这条原理,将各点连接起来,从而营造出线性变动的感觉(通常是沿着时间变动)。
运用连接律的最佳实践
视觉上相连的点必须有概念关联
用线连接起来的要素必须有概念关联。如图2.19所示,左侧的折线图就不恰当,因为产品与产品之间并无概念关联。产品的类别各不相同,最好用柱形图呈现。最常采用线性编码的变量是时间,因为这反映了随着时间变动的基础概念。
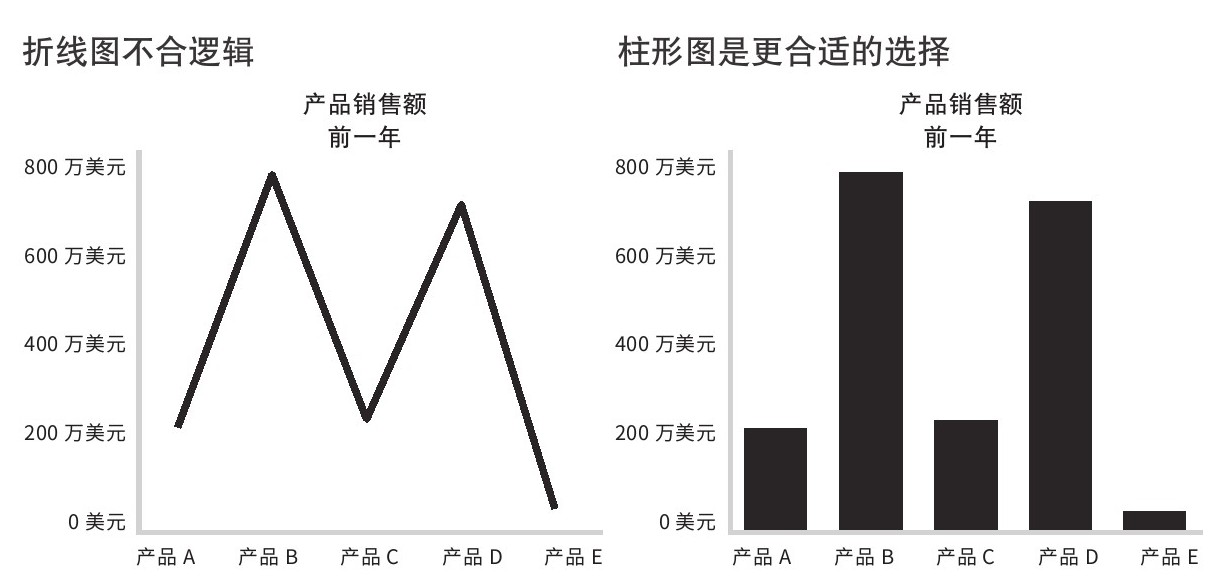
图2.19 折线图与柱形图的对比
相近律
我们会将靠近的元素视为属于同一个组别。
运用相近律的最佳实践
利用相近律来省掉图例
图例会加重受众的认知负荷,让他们不得不频繁转移视线,查看图中标示的类别。运用相近律可以让标签更直观,从而减轻认知负荷。
标签要紧贴对应的元素
人眼对远近非常敏感。在给数据图上的点或线加标签时,要让标签和对应元素离得尽可能近。远近的细小变化可能会对受众理解产生不成比例的影响。见图2.20。
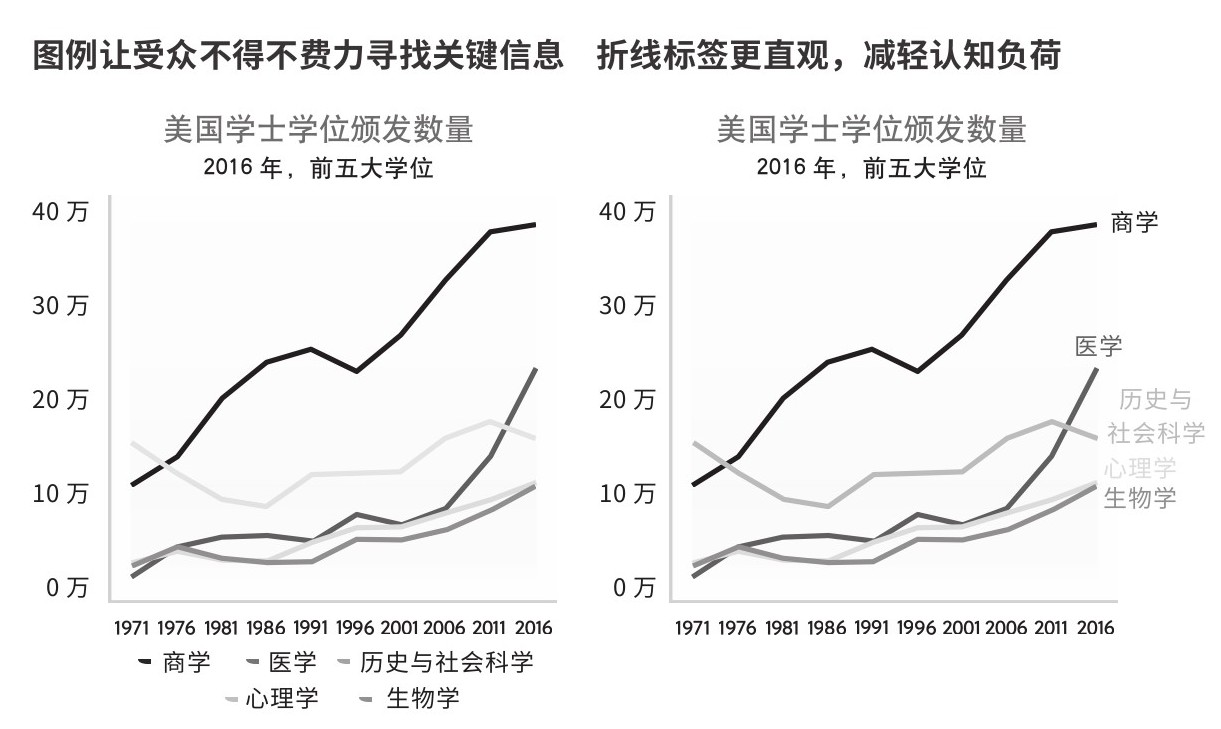
图2.20 标签的作用
来源:美国教育部国家教育统计中心,《高等教育综合信息调查》(HEGIS)。
相似律
我们会认为相似的东西属于同一组。运用这条原理,你可以让关联变得更清晰。标签和对应线条要采用相似的颜色,有助于强化两者之间的联系。
运用相似律的最佳实践
利用相似性强化标签的指代对象
标签和对应元素颜色要对应,以便进一步强化关联,如图2.21所示。
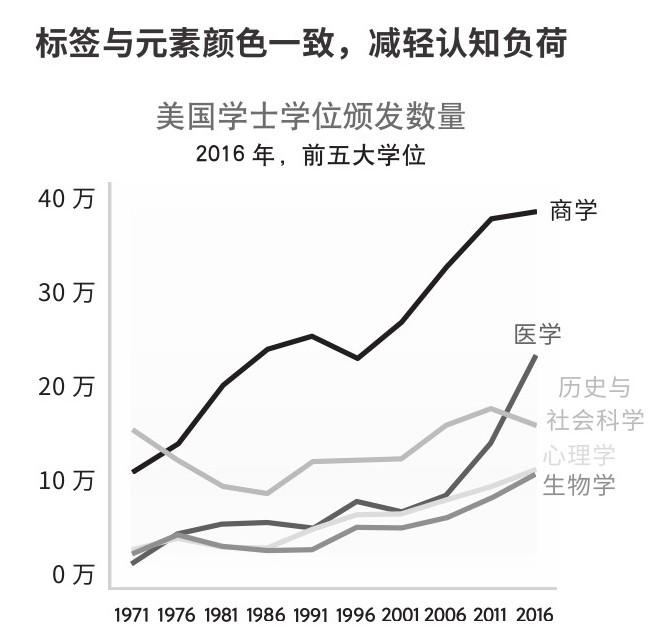
图2.21 标签与元素颜色对应
本章关键概念
虽然人类很擅长发现视觉关系,但我们在同一时间只能看到一个信息块,而且我们的注意力会被最突出的元素吸引。本章关键概念见表2.3—表2.5。
表2.3 我们在数据图里看到了什么
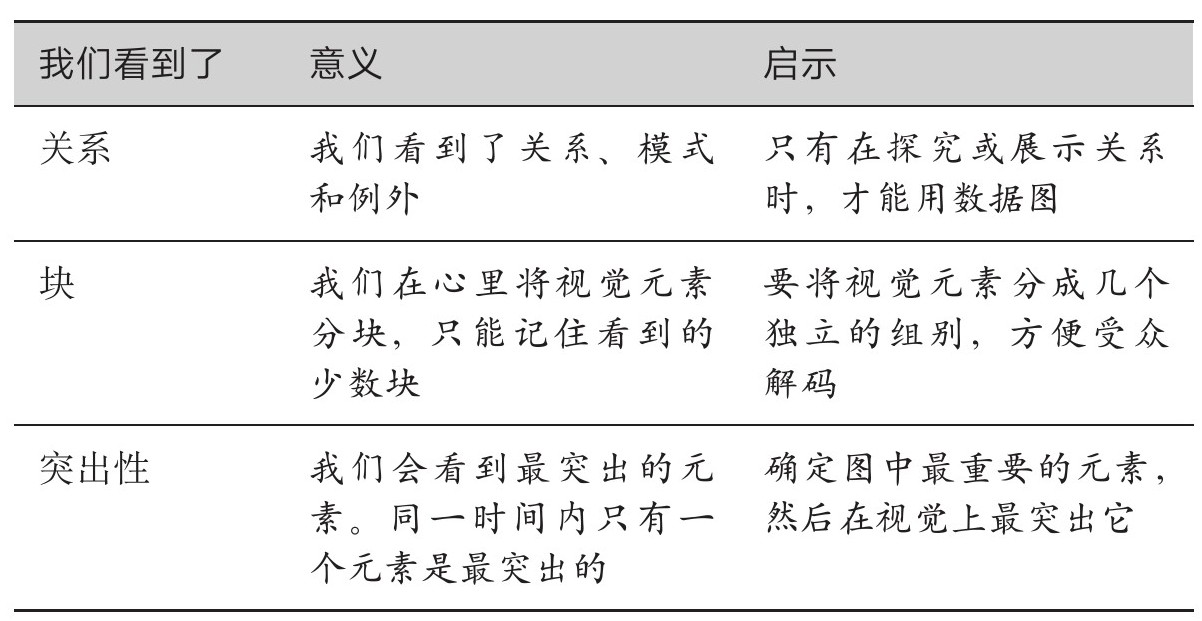
表2.4 利用前注意特征编码数据
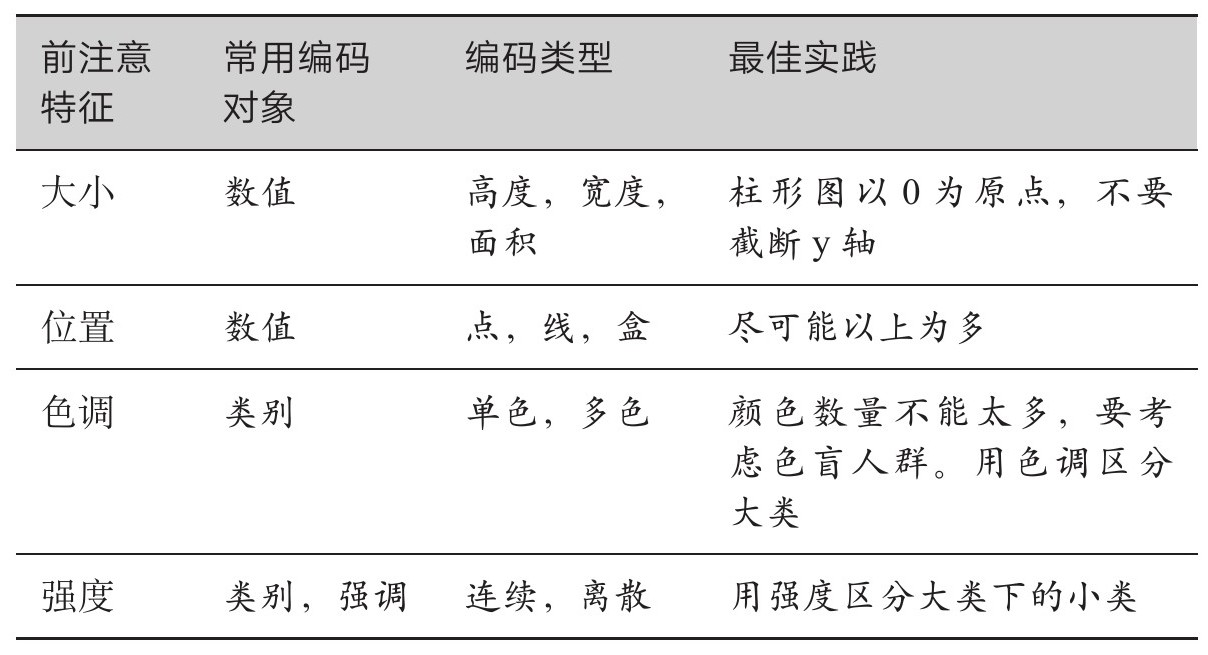
表2.5 适当运用格式塔原理,方便受众解码
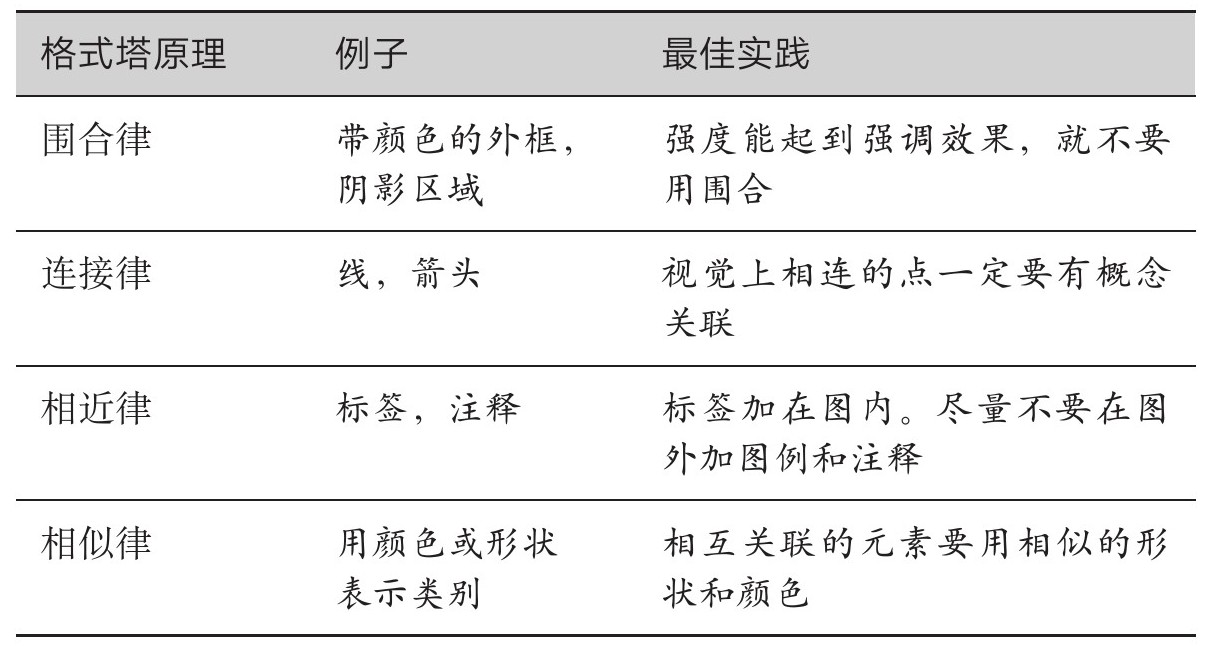
就算别的都记不住……
同一时间内能够主动处理的块数有严格限制。一般来说,我们一次能够处理三到四个块。
所有要素都突出,那就全都是噪声了。
如果数据确实需要复杂呈现,那请问一问自己:能不能把概念分到多张图中展示,从而减轻认知负荷。
习题:拆解数据图
分析图2.22和图2.23所示的两幅数据图。找出每一个用于编码信息的前注意特征,以及每一条表明数据关系的格式塔原理。在图中列出的数据之外,观察设计者用来减轻读者认知负荷的各种手段。请记住,同一条原理可以多次运用,运用方式各不相同。
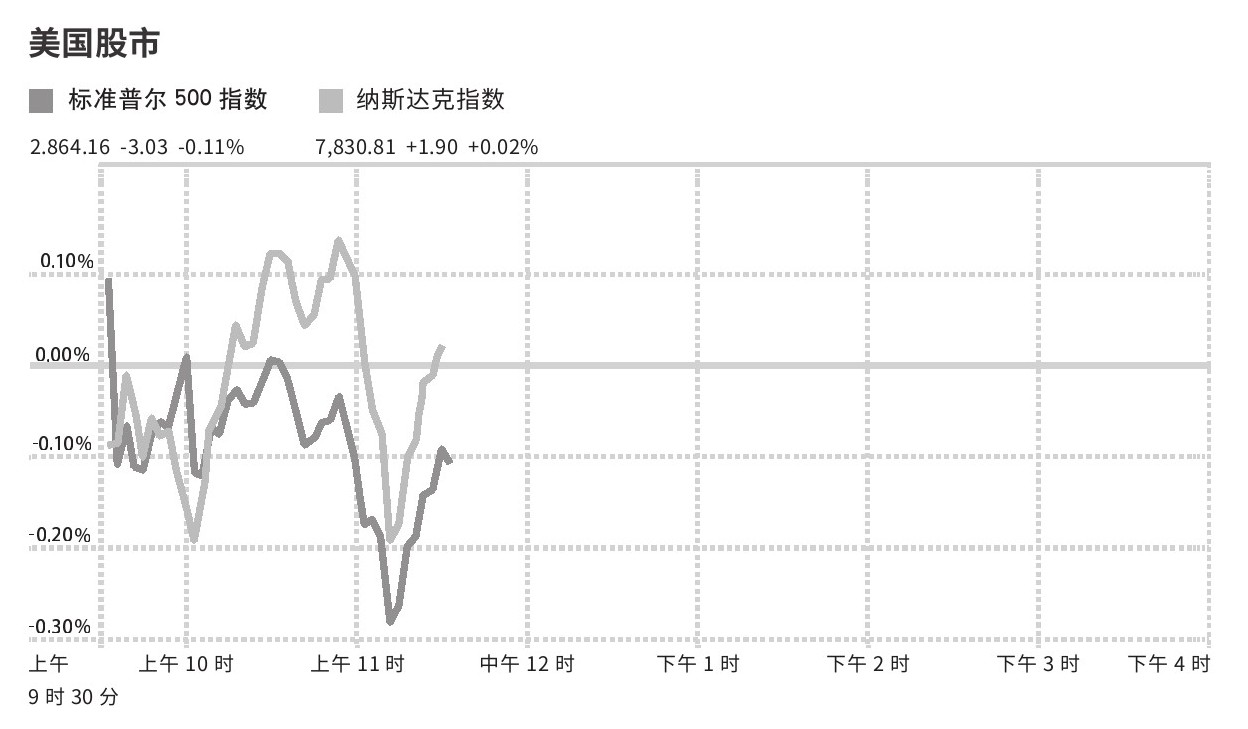
图2.22 习题1
来源:改编自《纽约时报》股市大盘。https://markets.on.nytimes.com/research/markets/overview/overview.asp.Accessed 4/2/2019 at 11:34 am。
填写表2.6和表2.7。
表2.6 习题1-1
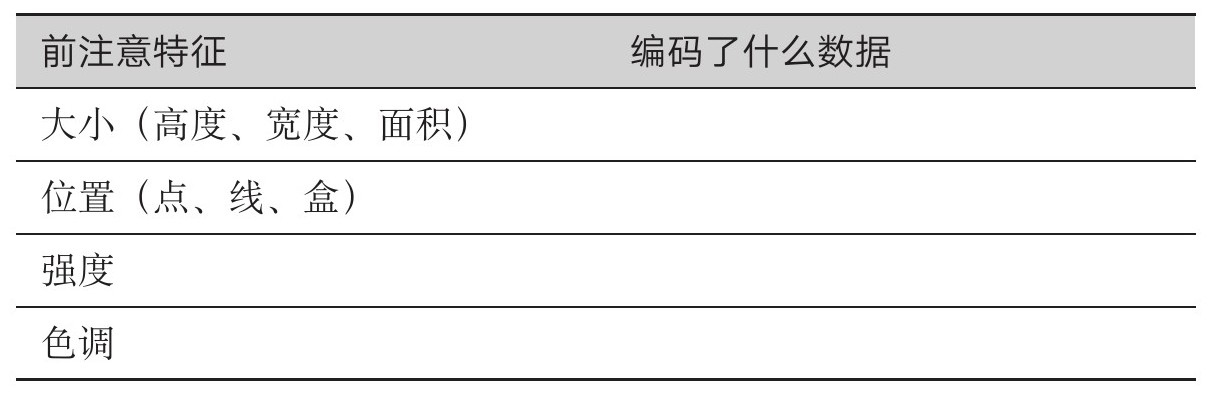
表2.7 习题1-2
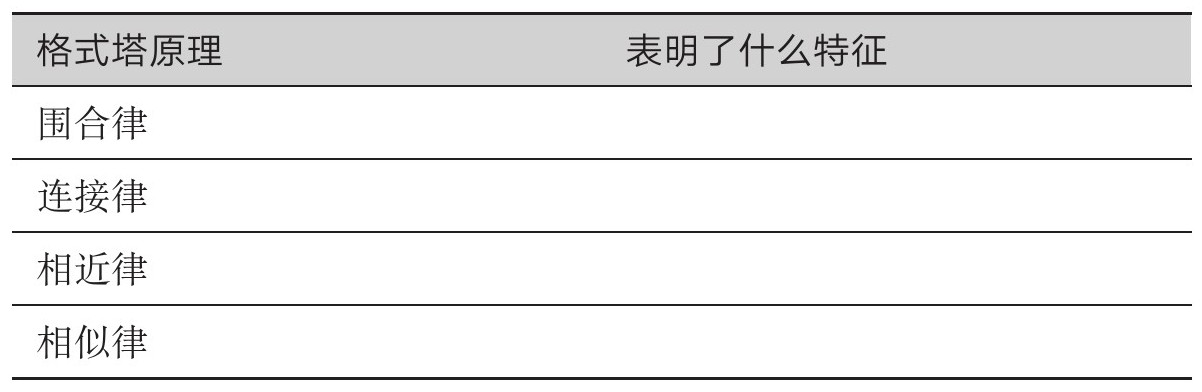
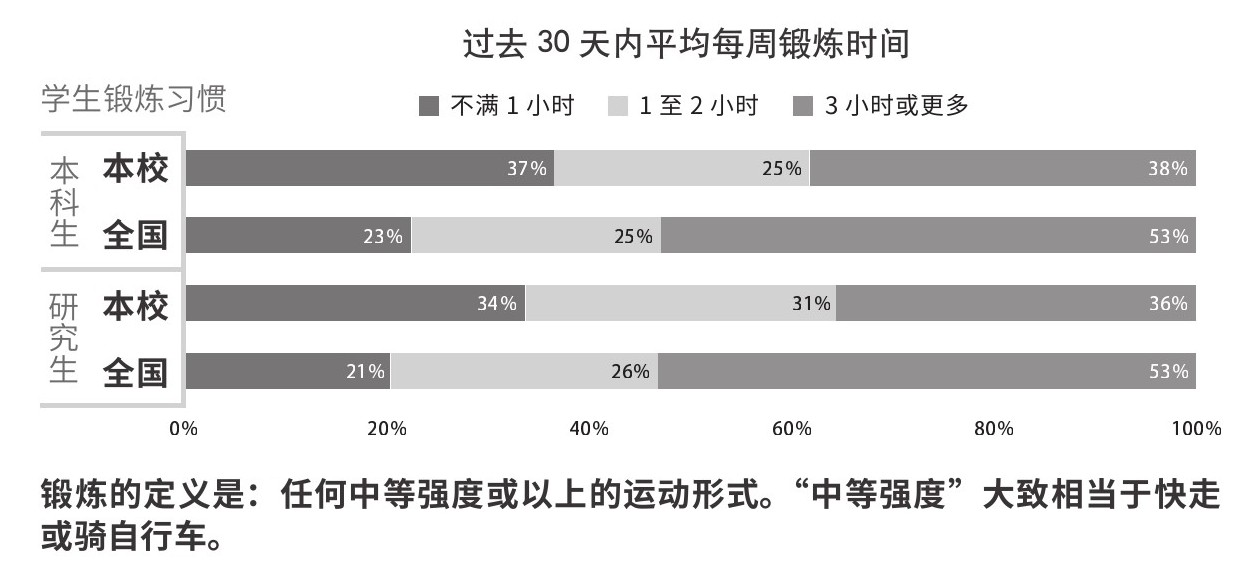
图2.23 学生锻炼习惯
填写表2.8和表2.9。
表2.8 习题2-1
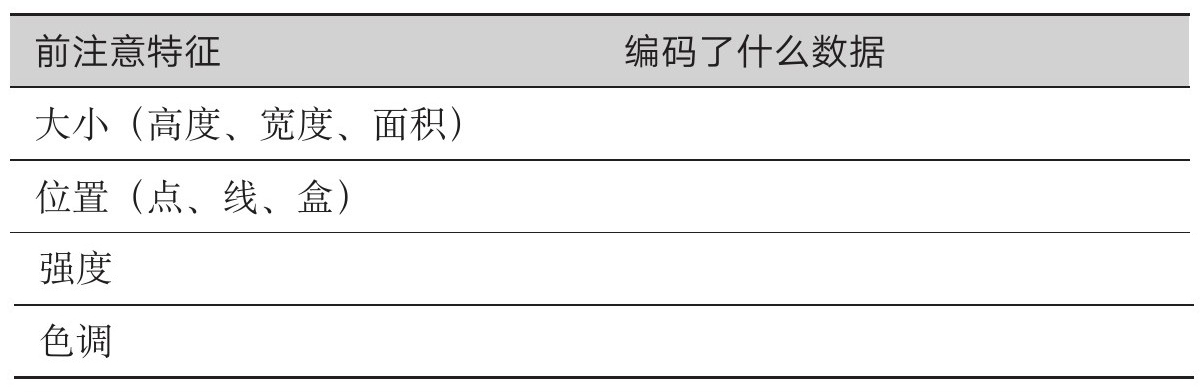
表2.9 习题2-2